Experiment Configuration¶
Launching experiments with the Maze command line interface (CLI) is based on the Hydra configuration system and hence also closely follows Hydra’s experimentation workflow. In general, there are different options for carrying out and configuring experiments with Maze. (To see experiment configuration in action, check out our project template.)
Command Line Overrides¶
To quickly play around with parameters in an interactive (temporary) fashion you can utilize Hydra command line overrides to reset parameters specified in the default config (e.g., conf_train).
maze-run -cn conf_train env.name=CartPole-v1 algorithm=ppo algorithm.lr=0.0001
The example above changes the trainer to PPO and optimizes with a learning rate of 0.0001. You can of course override any other parameter of your training and rollout runs.
For an in depth explanation of the override concept we refer to our Hydra documentation.
Experiment Config Files¶
For a more persistent way of structuring your experiments you can also make use of Hydra's built-in Experiment Configuration.
This allows you to maintain multiple experimental config files each only specifying the changes to the default config (e.g., conf_train).
# @package _global_
# defaults to override
defaults:
- _self_
- override /algorithm: ppo
- override /wrappers: vector_obs
# overrides
algorithm:
lr: 0.0001
The experiment config above sets the trainer to PPO, the learning rate to 0.0001 and additionally activates the vector_obs wrapper stack.
To start the training run with this config file, run:
maze-run -cn conf_train +experiment=cartpole_ppo_wrappers
You can find a more detail explanation on how experiments are embedded in the overall configuration system in our Hydra experiment documentation.
Hyper Parameter Grid Search¶
To perform a simple grid search over selected hyper parameters you can use Hydra's Sweeper which converts lists of command line arguments into distinct jobs.
The example below shows how to launch the same experiment with three different learning rates.
maze-run -cn conf_train env.name=CartPole-v1 algorithm=ppo algorithm.n_epochs=5 algorithm.lr=0.0001,0.0005,0.001 --multirun
We then recommend to compare the different configurations with Tensorboard.
tensorboard --logdir outputs/
Within tensorboard the hyperparameters of the grid search are logged as well, which makes comparison between runs more convenient as can be seen in the figure below:
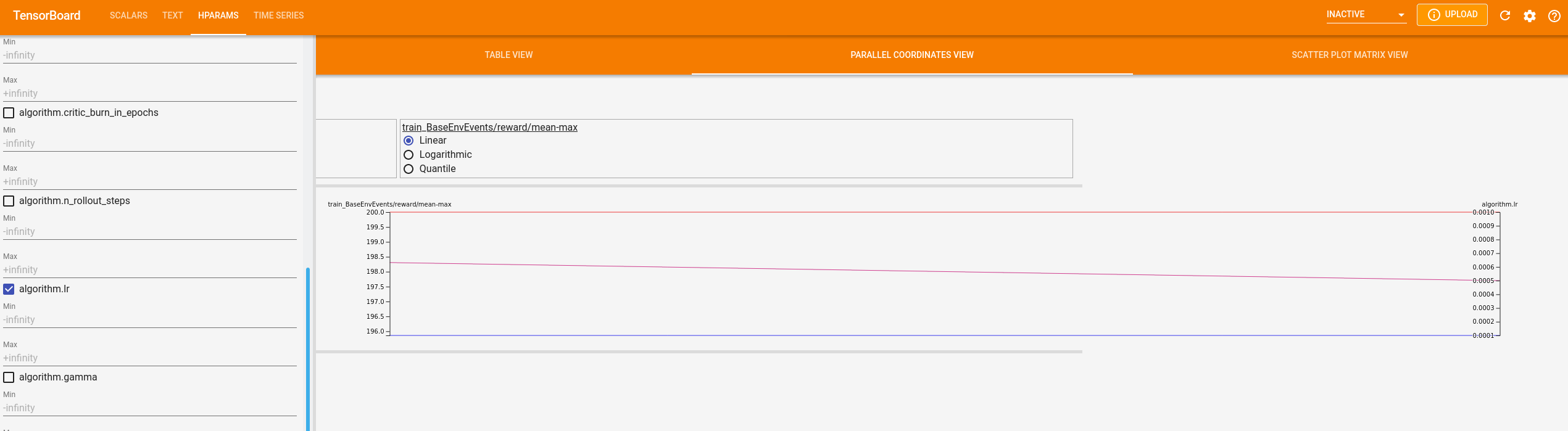
Per default Hydra uses the local (sequential) runner for processing jobs.
For setting up a more scalable (local, parallel) grid search
we recommend to create an experiments file for configuration.
As a starting point Maze already contains a simple local grid search setting
based on the built-in MazeLocalLauncher.
# @package _global_
# defaults to override
defaults:
- _self_
- override /runner: local
- override /hydra/launcher: local
# set training runner concurrency
runner:
concurrency: 0
# set grid search concurrency
hydra:
launcher:
# maximum number of parallel grid search jobs
# if -1, this is set to the number of CPUs
n_jobs: 4
# Hint: make sure that runner.concurrency * hydra.launcher.n_jobs <= CPUs
To repeat the grid search from above, but this time with multiple parallel workers, run:
maze-run -cn conf_train env.name=CartPole-v1 algorithm=ppo algorithm.n_epochs=5 algorithm.lr=0.0001,0.0005,0.001 +experiment=grid_search --multirun
Besides the built-in MazeLocalLauncher,
there are also more scalable options available with Hydra.
Hyperparameter Optimization¶
Maze also support hyper parameter optimization beyond vanilla grid search via Nevergrad (in case you have enough resources available).
You can start with the experiment template below and adopt it to your needs (for details on how to define the search space we refer to the Hydra docs and this example).
# @package _global_
# defaults to override
defaults:
- _self_
- override /algorithm: ppo
- override /hydra/sweeper: nevergrad
- override /hydra/launcher: local
- override /runner: local
# set training runner concurrency
runner:
concurrency: 0
# overrides
hydra:
sweeper:
optim:
# name of the nevergrad optimizer to use
# OnePlusOne is good at low budget, but may converge early
optimizer: OnePlusOne
# total number of function evaluations to perform
budget: 100
# number of parallel workers for performing function evaluations
num_workers: 4
# we want to maximize reward
maximize: true
# default parametrization of the search space
parametrization:
# a linearly-distributed scalar
algorithm.lr:
lower: 0.00001
upper: 0.001
algorithm.entropy_coef:
lower: 0.0000025
upper: 0.025
# Hint: make sure that runner.concurrency * hydra.sweeper.optim.num_workers <= CPUs
To start a hyper parameter optimization, run:
maze-run -cn conf_train env.name=Pendulum-v0 algorithm.n_epochs=5 +experiment=nevergrad --multirun
Where to Go Next¶
Here you can learn how to set up a custom configuration/experimentation module.
If you would like to learn about more advanced configuration options you can dive into the Hydra configuration system documentation.
Clone this project template to start your own Maze project.