Multi-Agent RL¶
Note
- Recommended prior to this article:
Multi-agent reinforcement learning (MARL) describes a setup in which several collaborating or competing agents suggest actions for at least one of an environment’s acting entitites [1] each. This introduces the additional complexity of emergent effects between those agents. Some problems require to or at least benefit from deviating from a single-agent formulation, such as the vehicle routing problem, (video) games like Starcraft, traffic coordination, power systems and smart grids and many others.
Maze supports multi-agent learning via structured environment. In order to make a StructuredEnv compatible with such a setup, it needs to keep track of the activities of each agent internally. How this is done and the order in which sequence agents enacted their actions is entirely to the environment. As per customary for a structured environment, it is required to provide the ID of the active actor via actor_id() (see here for more information on the distinction between actor and agent). There are no further prequisites to use multiple agents with an environment.
Control Flow¶
It is easily possible, but not necessary, to include multiple policies in a multi-agent scenario. The control flow with multiple agents and a single policy can be summarized like this:
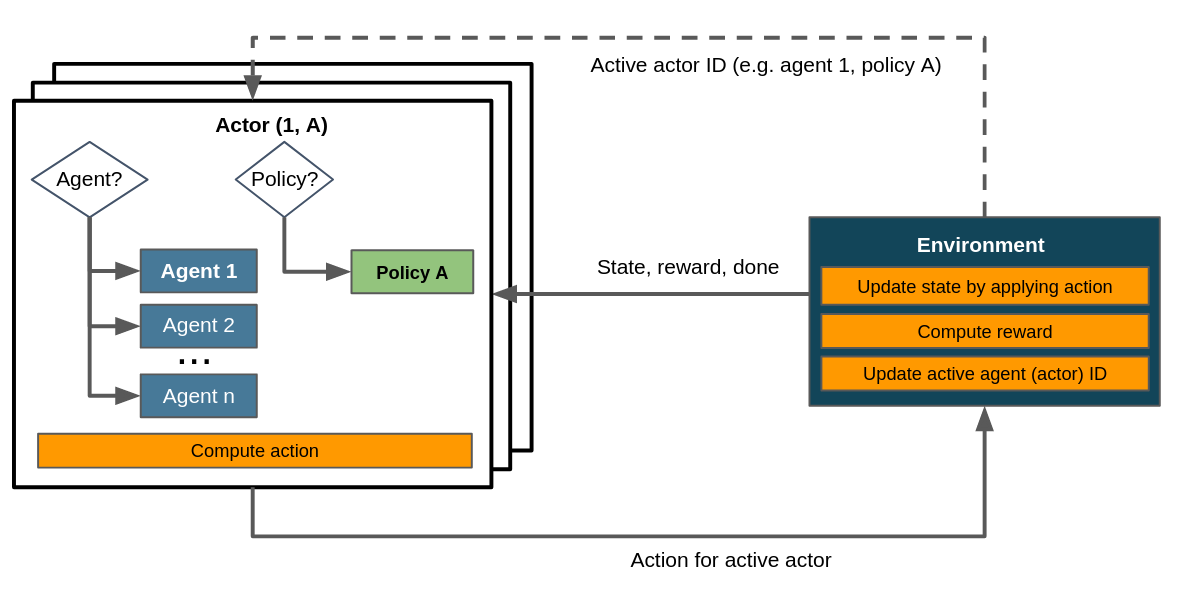
Control flow within a multi-agent scenario assuming a single policy. Dashed lines denote the exchange of information on demand as opposed to doing so passing it to or returning it from step().¶
When comparing this to the control flow depicted in the article on flat environments you’ll notice that here we consider several agents and therefore several actors - more specifically, in a setup with n agents we have at least n actors. Consequently the environment has to update its active actor ID, which is not necessary in flat environments.
Where to Go Next¶
Gym-style flat environments as a special case of structured environments.
Multi-stepping applies the actor mechanism to enact several policies in a single step.
Hierarchical RL by chaining and nesting tasks via policies..