Event and KPI Logging¶
Monitoring only standard metrics such as reward or episode step count is not always sufficiently informative about the agent’s behaviour and the problem at hand. To tackle this issue and to enable better inspection and logging tools for both, agents and environments, we introduce an event and key performance indicator (KPI) logging system. It is based on the more general event system and allows us to log and monitor environment specific metrics.
The figure below shows a conceptual overview of the logging system. In the remainder of this page we will go through the components in more detail.
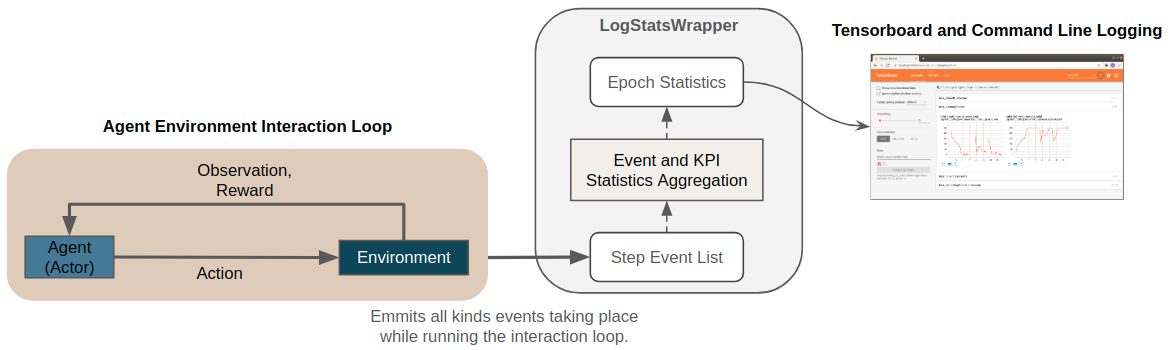
Events¶
In this section we describe the event logging system from an usage perspective. To understand how this is embedded in the broader context of a Maze environment we refer to the environments and KPI section of our step by step tutorial as well as the dedicated section on the underlying event system.
In general, events can be define for any component involved in the RL process (e.g., environments, agents, …).
They get fired by the respective component whenever they occur during the agent environment interaction loop.
For logging, events are collected and aggregated via the
LogStatsWrapper.
To provide full flexibility Maze allows to customize which statistics are computed
at which stage of the aggregation process via event decorators (step, episode, epoch).
The code snipped below contains an example for an event called invalid_piece_selected
borrowed from the cutting 2D tutorial.
class CuttingEvents(ABC):
"""Events related to the cutting process."""
@define_epoch_stats(np.mean, output_name="mean_episode_total")
@define_episode_stats(sum)
@define_step_stats(len)
def invalid_piece_selected(self):
"""An invalid piece is selected for cutting."""
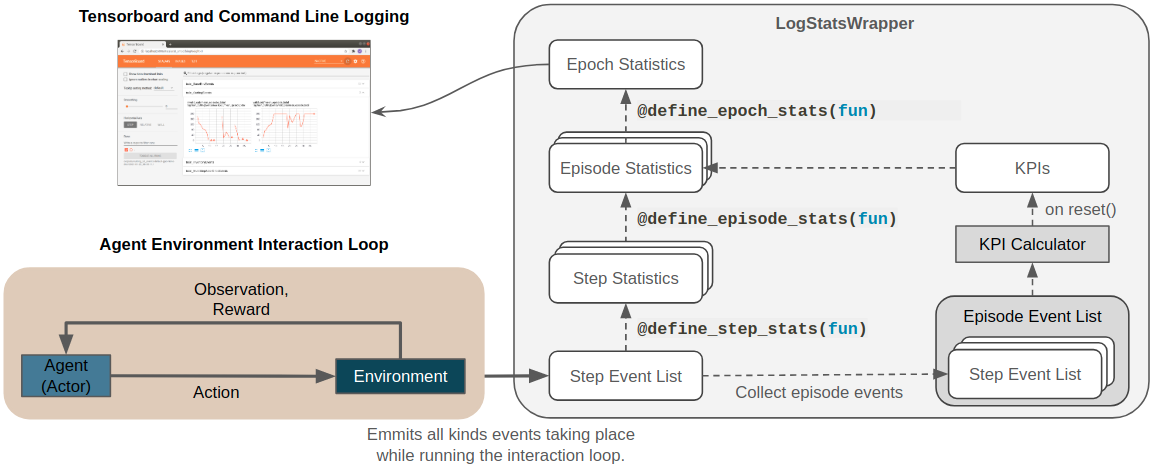
The snippet defines the following statistics aggregation hierarchy:
Step Statistics [@define_step_stats(len)]:
in each environment step events \(e_i\) are collected as lists of events \(\{e_i\}\).
The function len associated with the decorator counts
how often such an event occurred in the current step \(Stats_{Step}=|\{e_i\}|\)
(e.g., length of invalid_piece_selected event list).
Episode Statistics [@define_episode_stats(sum)]:
defines how the \(S\) step statistics should be aggregated to episode statistics
(e.g., by simply summing them up: \(Stats_{Episode}=\sum^S Stats_{Step})\)
Epoch Statistics [@define_epoch_stats(np.mean, output_name="mean_episode_total")]:
a training epoch consists of N episodes.
This stage defines how these N episode statistics are averaged to epoch statistics
(e.g., the mean of the contained episodes: \(Stats_{Epoch}=(\sum^N Stats_{Episode})/N\)).
The figure below provides a visual summary of the entire event statistics aggregation hierarchy as well as its relation to KPIs which will be explained in the next section. In Tensorboard and on the command line these events get then logged in dedicated sections (e.g., as CuttingEvents).
Key Performance Indicators (KPIs)¶
In applied RL settings the reward is not always the target metric
we aim at optimizing from an economical perspective.
Sometimes rewards are heavily shaped to get the agent to learn the right behaviour.
This makes it hard to interpret for humans.
For such cases Maze supports computing and logging of additional Key Performance Indicators (KPIs)
along with the reward via the KpiCalculator
implemented as a part of the CoreEnv (as reward KPIs are logged as BaseEnvEvents).
KPIs are in contrast to events computed in an aggregated form at the end of an episode
triggered by the reset() method of the
LogStatsWrapper.
This is why we can compute them in a normalized fashion (e.g., dived by the total number of steps in an episode).
Conceptually KPIs life on the same level as episode statistics in the logging hierarchy (see figure above).
For further details on how to implement a concrete KPI calculator we refer to the KPI section of our tutorial.
Plain Python Configuration¶
When working with the CLI and Hydra configs all components necessary for logging are automatically instantiated under the hood. In case you would like to test or run your logging setup directly from Python you can start with the snippet below.
from docs.tutorial_maze_env.part04_events.env.maze_env import maze_env_factory
from maze.utils.log_stats_utils import SimpleStatsLoggingSetup
from maze.core.wrappers.log_stats_wrapper import LogStatsWrapper
# init maze environment
env = maze_env_factory(max_pieces_in_inventory=200, raw_piece_size=[100, 100],
static_demand=(30, 15))
# wrap environment with logging wrapper
env = LogStatsWrapper(env, logging_prefix="main")
# register a console writer and connect the writer to the statistics logging system
with SimpleStatsLoggingSetup(env):
# reset environment and run interaction loop
obs = env.reset()
for i in range(15):
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
To get access to event and KPI logging we need to wrap the environment with the
LogStatsWrapper.
To simplify the statistics logging setup we rely on the
SimpleStatsLoggingSetup helper class.
When running the script you will get an output as shown below. Note that statistics of both, events and KPIs, are printed along with default reward or action statistics.
step|path | value
=====|==========================================================================|====================
1|main DiscreteActionEvents action substep_0/order | [len:15, μ:0.5]
1|main DiscreteActionEvents action substep_0/piece_idx | [len:15, μ:82.3]
1|main DiscreteActionEvents action substep_0/rotation | [len:15, μ:0.7]
1|main BaseEnvEvents reward median_step_count | 15.000
1|main BaseEnvEvents reward mean_step_count | 15.000
1|main BaseEnvEvents reward total_step_count | 15.000
1|main BaseEnvEvents reward total_episode_count | 1.000
1|main BaseEnvEvents reward episode_count | 1.000
1|main BaseEnvEvents reward std | 0.000
1|main BaseEnvEvents reward mean | -29.000
1|main BaseEnvEvents reward min | -29.000
1|main BaseEnvEvents reward max | -29.000
1|main InventoryEvents piece_replenished mean_episode_total | 3.000
1|main InventoryEvents pieces_in_inventory step_max | 200.000
1|main InventoryEvents pieces_in_inventory step_mean | 200.000
1|main CuttingEvents invalid_cut mean_episode_total | 14.000
1|main InventoryEvents piece_discarded mean_episode_total | 2.000
1|main CuttingEvents valid_cut mean_episode_total | 1.000
1|main BaseEnvEvents kpi max/raw_piece_usage_..| 0.000
1|main BaseEnvEvents kpi min/raw_piece_usage_..| 0.000
1|main BaseEnvEvents kpi std/raw_piece_usage_..| 0.000
1|main BaseEnvEvents kpi mean/raw_piece_usage..| 0.000
Where to Go Next¶
You can learn more about the general event system.
For a more implementation oriented summary you can visit the events and KPI section of our tutorial.
To see another application of the event system you can read up on reward customization and shaping.