Turning a “flat” MazeEnv into a StructuredEnv¶
In this part of the tutorial we will learn how to reformulate an RL problem in order to turn it from a “flat” Gym-style environment into a structured environment.
The complete code for this part of the tutorial can be found here
# relevant files
- cutting_2d
- main.py
- env
- struct_env.py
Analyzing the Problem Structure¶
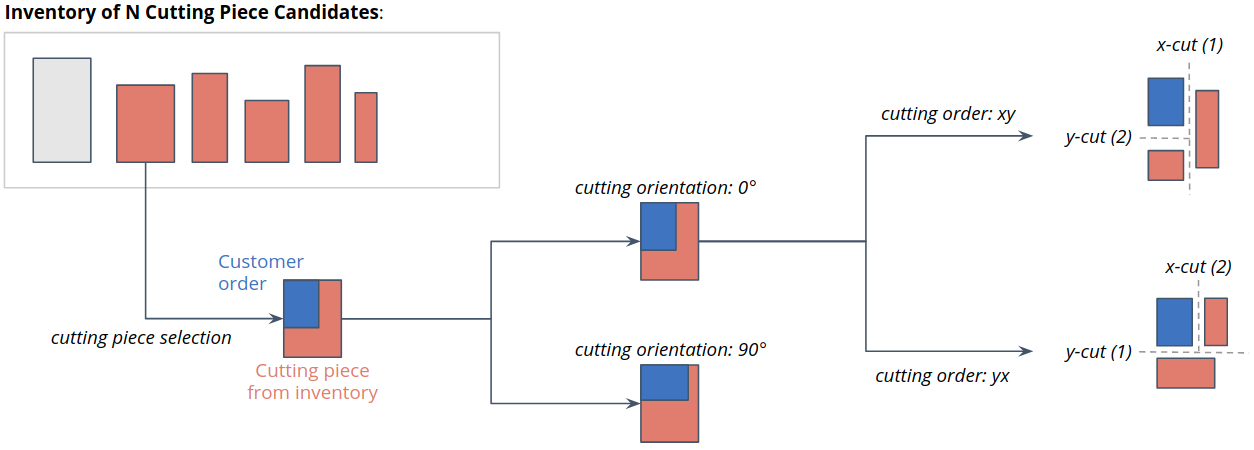
Before we start implementing the structured environment lets first revisit the cutting 2D problem. In particular, we put our attention to the joint action space consisting of the following components:
Action \(a_0\): cutting piece selection (decides which piece from inventory to use for cutting)
Action \(a_1\): cutting orientation selection (decides on the orientation of the cut)
Action \(a_2\): cutting order selection (decides which cut to take first; x or y)
Analysis of Action Space and Problem:
We are facing a combinatorial action space with \(O(N \cdot 2 \cdot 2)\) possible actions the agent has to choose from in each step. \(N\) is the maximum number of pieces stored in the inventory.
Sampling from this joint action space might result in invalid cutting configurations. This is because the three sub-actions are treated independently from each other. For the problem at hand this is obviously not the case.
It would be much more intuitive to sample the sub-actions sequentially and conditioned on each other. (E.g., it seems to be easier to decide on the cutting order and orientation once we know the piece we will cut from.)
Implementing the Structured Environment¶
We now address the issues discovered in the previous section and re-formulate the cutting 2D problem as a
StructuredEnv with the following two sub-steps:
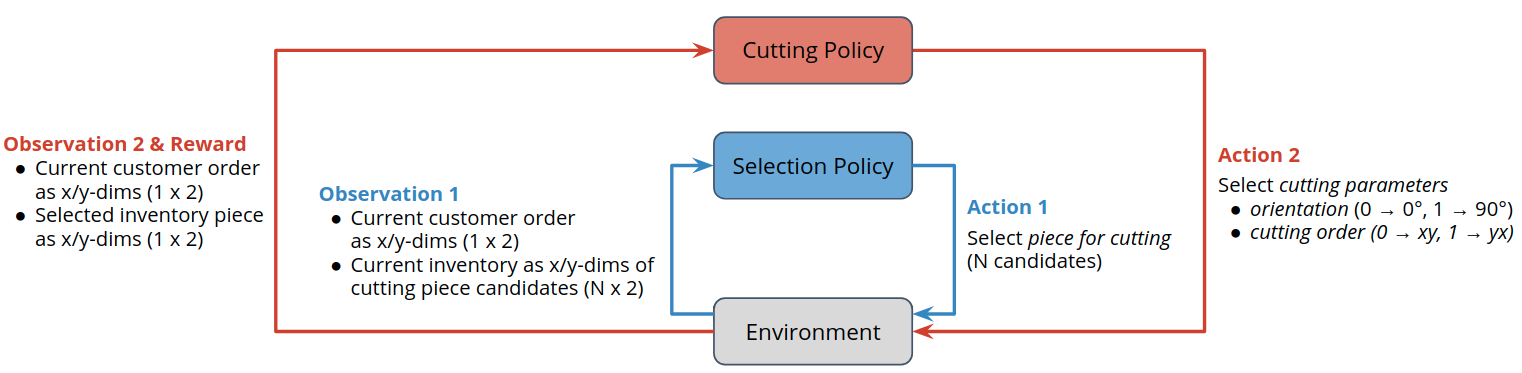
Select cutting piece from inventory given inventory state and customer order.
Select cutting configuration (cutting order and cutting orientation) given customer order and inventory cutting piece selected in the previous sub-step.
This could be also described with the modified agent environment interaction loop shown in the figure below. Note that the both observation and action space differ between the selection and the cutting sub-step. For the present example, reward is only granted once the cutting sub-step (i.e., the second step) is complete.
Note
Conceptually structured environments and conditional sub-steps are related to auto-regressive action spaces where subsequent actions are sampled conditioned on their predecessors. [e.g. DeepMind (2019), “Grandmaster level in StarCraft II using multi-agent reinforcement learning.”]
The code for the StructuredCutting2DEnvironment below implements exactly this interaction pattern.
from copy import deepcopy
from typing import Dict, Any, Union, Tuple, Optional, List
import gymnasium as gym
import numpy as np
from maze.core.env.maze_action import MazeActionType
from maze.core.env.maze_env import MazeEnv
from maze.core.env.maze_state import MazeStateType
from maze.core.env.structured_env import StructuredEnv, ActorID
from maze.core.env.structured_env_spaces_mixin import StructuredEnvSpacesMixin
from maze.core.wrappers.wrapper import Wrapper
from .maze_env import maze_env_factory
class StructuredCutting2DEnvironment(Wrapper[MazeEnv], StructuredEnv, StructuredEnvSpacesMixin):
"""Structured environment version of the cutting 2D environment.
The environment alternates between the two sub-steps:
- Select cutting piece
- Select cutting configuration (cutting order and cutting orientation)
:param maze_env: The "flat" cutting 2D environment to wrap.
"""
def __init__(self, maze_env: MazeEnv):
Wrapper.__init__(self, maze_env)
# define sub-step action spaces
self._action_spaces_dict = {
0: gym.spaces.Dict({"piece_idx": maze_env.action_space["piece_idx"]}),
1: gym.spaces.Dict({"cut_rotation": maze_env.action_space["cut_rotation"],
"cut_order": maze_env.action_space["cut_order"]})
}
# define sub-step observation spaces
flat_space = maze_env.observation_space
self._observation_spaces_dict = {
0: flat_space,
1: gym.spaces.Dict({"selected_piece": flat_space["ordered_piece"],
"ordered_piece": flat_space["ordered_piece"]})
}
self._flat_obs = None
self._action_0 = None
self._sub_step_key = 0
self._last_reward = None # Last reward obtained from the underlying environment
def step(self, action):
"""Generic step function alternating between the two sub-steps.
:return: obs, rew, done, info
"""
# sub-step: Select cutting piece
if self._sub_step_key == 0:
sub_step_result = self._selection_step(action)
# sub-step: Select cutting configuration
elif self._sub_step_key == 1:
sub_step_result = self._cutting_step(action)
else:
raise ValueError("Sub-step id {} not allowed for this environment!".format(self._sub_step_key))
# alternate step index
self._sub_step_key = np.mod(self._sub_step_key + 1, 2)
return sub_step_result
def reset(self) -> Any:
"""Resets the environment and returns the initial state.
:return: The initial state after resetting.
"""
self._flat_obs = self.env.reset()
self._flat_obs["ordered_piece"] = self._flat_obs["ordered_piece"]
self._sub_step_key = 0
return self._obs_selection_step(self._flat_obs)
@staticmethod
def _obs_selection_step(flat_obs: Dict[str, np.array]) -> Dict[str, np.array]:
"""Formats initial observation / observation available for the first sub-step."""
return deepcopy(flat_obs)
@staticmethod
def _obs_cutting_step(flat_obs: Dict[str, np.array], selected_piece_idx: int) -> Dict[str, np.array]:
"""Formats observation available for the second sub-step."""
return {"selected_piece": flat_obs["inventory"][selected_piece_idx],
"ordered_piece": flat_obs["ordered_piece"]}
def _selection_step(self, action: Dict[str, int]) -> Tuple[Dict[str, np.ndarray], float, bool, Dict]:
"""Cutting piece selection step."""
self._action_0 = action
obs = self._obs_cutting_step(self._flat_obs, action["piece_idx"])
return obs, 0.0, False, {}
def _cutting_step(self, action: Dict[str, int]) -> Tuple[Dict[str, np.ndarray], float, bool, Dict]:
"""Cutting rotation and cutting order selection step."""
flat_action = {"piece_idx": self._action_0["piece_idx"],
"cut_rotation": action["cut_rotation"],
"cut_order": action["cut_order"]}
self._flat_obs, self._last_reward, done, info = self.env.step(flat_action)
self._flat_obs["ordered_piece"] = self._flat_obs["ordered_piece"]
return self._obs_selection_step(self._flat_obs), self._last_reward, done, info
def actor_id(self) -> ActorID:
"""Returns the currently executed actor along with the policy id. The id is unique only with
respect to the policies (every policy has its own actor 0).
Note that identities of done actors can not be reused in the same rollout.
:return: The current actor, as tuple (policy id, actor number).
"""
return ActorID(step_key=self._sub_step_key, agent_id=0)
def get_actor_rewards(self) -> Optional[np.ndarray]:
"""Returns rewards attributed to individual actors after the step has been done. This is necessary,
as after the first sub-step (i.e., piece selection), the full reward is not yet available, so zero
reward is returned instead. The second (= last) sub-step then returns joint reward for all (both) actors.
With this method, we can attribute parts of the reward to the individual actors, which is useful for example
if each has its own separate critic.
In this case, we attribute half of the reward to each actor.
"""
return np.array([self._last_reward / 2.0] * 2)
@property
def agent_counts_dict(self) -> Dict[Union[str, int], int]:
"""Returns the count of agents for individual sub-steps (or -1 for dynamic agent count).
This env has two sub-steps (0 and 1), in each of which one agent gets to act. Hence, we return
{0: 1, 1: 1}.
"""
return {0: 1, 1: 1}
def is_actor_done(self) -> bool:
"""Returns True if the just stepped actor is done, which is different to the done flag of the environment."""
return False
@property
def action_space(self) -> gym.spaces.Dict:
"""Implementation of :class:`~maze.core.env.structured_env_spaces_mixin.StructuredEnvSpacesMixin` interface."""
return self._action_spaces_dict[self._sub_step_key]
@property
def observation_space(self) -> gym.spaces.Dict:
"""Implementation of :class:`~maze.core.env.structured_env_spaces_mixin.StructuredEnvSpacesMixin` interface."""
return self._observation_spaces_dict[self._sub_step_key]
@property
def action_spaces_dict(self) -> Dict[Union[int, str], gym.spaces.Dict]:
"""Implementation of :class:`~maze.core.env.structured_env_spaces_mixin.StructuredEnvSpacesMixin` interface."""
return self._action_spaces_dict
@property
def observation_spaces_dict(self) -> Dict[Union[int, str], gym.spaces.Dict]:
"""Implementation of :class:`~maze.core.env.structured_env_spaces_mixin.StructuredEnvSpacesMixin` interface."""
return self._observation_spaces_dict
def seed(self, seed: int = None) -> None:
"""Sets the seed for this environment's random number generator(s).
:param: seed: the seed integer initializing the random number generator.
"""
self.env.seed(seed)
def close(self) -> None:
"""Performs any necessary cleanup."""
self.env.close()
def get_observation_and_action_dicts(self, maze_state: MazeStateType, maze_action: MazeActionType,
first_step_in_episode: bool) \
-> Tuple[Optional[Dict[Union[int, str], Any]], Optional[Dict[Union[int, str], Any]]]:
"""Convert the flat action and MazeAction from Maze env into the structured ones.
Note that both MazeState and MazeAction needs to be supplied together, otherwise actions/observations for the
individual sub-steps cannot be produced.
"""
assert maze_state is not None and maze_action is not None,\
"This wrapper needs both MazeState and MazeAction for the conversion (as there are multiple sub-steps)."
observation_dict, action_dict = self.env.get_observation_and_action_dicts(maze_state, maze_action,
first_step_in_episode)
assert len(observation_dict.items()) == 1 and len(action_dict.items()) == 1, "wrapped env should be single-step"
flat_action = list(action_dict.values())[0]
flat_obs = list(observation_dict.values())[0]
flat_obs["ordered_piece"] = flat_obs["ordered_piece"]
obs_dict = {
0: self._obs_selection_step(flat_obs),
1: self._obs_cutting_step(flat_obs, flat_action["piece_idx"])
}
act_dict = {
0: {k: flat_action[k] for k in ["piece_idx"]},
1: {k: flat_action[k] for k in ["cut_rotation", "cut_order"]}
}
return obs_dict, act_dict
def struct_env_factory(max_pieces_in_inventory: int, raw_piece_size: Tuple[int, int],
static_demand: List[Tuple[int, int]]) -> StructuredCutting2DEnvironment:
"""Convenience factory function that compiles a trainable structured environment.
(for argument details see: Cutting2DEnvironment)
"""
# init maze environment including observation and action interfaces
env = maze_env_factory(max_pieces_in_inventory=max_pieces_in_inventory,
raw_piece_size=raw_piece_size,
static_demand=static_demand)
# convert flat to structured environment
return StructuredCutting2DEnvironment(env)
Test Script¶
The following snippet first instantiates the structured environment and then performs one cycle of the structured agent environment interaction loop.
""" Test script CoreEnv """
from tutorial_maze_env.part06_struct_env.env.struct_env import struct_env_factory
def main():
# init maze environment including observation and action interfaces
struct_env = struct_env_factory(max_pieces_in_inventory=200,
raw_piece_size=(100, 100),
static_demand=[(30, 15)])
# reset env
obs_step1 = struct_env.reset()
print("action_space 1: ", struct_env.action_space)
print("observation_space 1:", struct_env.observation_space)
print("observation 1: ", obs_step1.keys())
# take first env step
action_1 = struct_env.action_space.sample()
obs_step2, rew, done, info = struct_env.step(action=action_1)
print("action_space 2: ", struct_env.action_space)
print("observation_space 2:", struct_env.observation_space)
print("observation 2: ", obs_step2.keys())
# take second env step
action_2 = struct_env.action_space.sample()
obs_step1 = struct_env.step(action=action_2)
if __name__ == "__main__":
""" main """
main()
Running the script will print the following output. Note that the observation and action spaces alternate from sub-step to sub-step.
action_space 1: Dict(piece_idx:Discrete(200))
observation_space 1: Dict(inventory:Box(200, 2), inventory_size:Box(1,), order:Box(2,))
observation 1: dict_keys(['inventory', 'inventory_size', 'order'])
action_space 2: Dict(order:Discrete(2), rotation:Discrete(2))
observation_space 2: Dict(order:Box(2,), selected_piece:Box(1, 2))
observation 2: dict_keys(['selected_piece', 'order'])
In the next part of this tutorial we will train an agent on this structured environment.