Structured Environments and Action Masking¶
This tutorial provides a step by step guide explaining how to implement a decision problem
as a structured environment and how to train an agent for such a StructuredEnv
with a structured Maze Trainer.
The examples are again based on the online version of the Guillotine 2D Cutting Stock Problem
which is a perfect fit for introducing the underlying concepts.
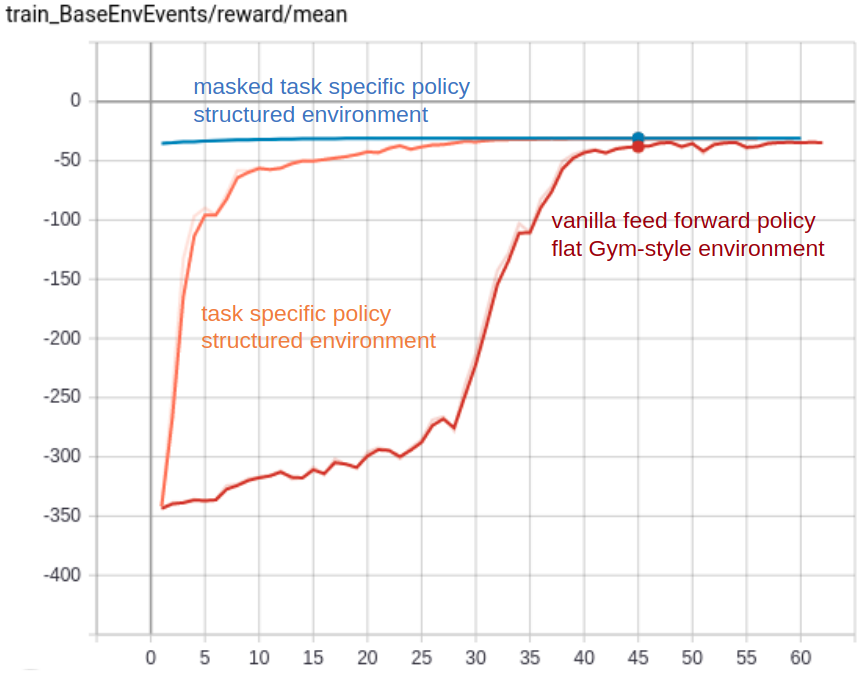
In particular, we will see how to evolve the performance of an RL agent by going through the following stages:
Flat Gym-style environment with vanilla feed forward models
Structured environment (e.g., with hierarchical sub-steps) with task specific policy networks
Structured environment (e.g., with hierarchical sub-steps) with masked task specific policy networks
Before diving into this tutorial we recommend to familiarize yourself with Control Flows with Structured Environments and the basic Maze - step by step tutorial.
The remainder of this tutorial is structured as follows:
Turning a “flat” MazeEnv into a StructuredEnv
We will reformulate the problem from a “flat” Gym-style environment into a structured environment.
Training the Structured Environment
We will train the structured environment with a Maze Trainer.
Adding Step-Conditional Action Masking
We will learn how to substantially increase the sample efficiency by adding step-conditional action masking.
Training with Action Masking
We will retrain the structured environment with step-conditional action masking activated
and benchmark it with the initial version environment.