Working with Template Models¶
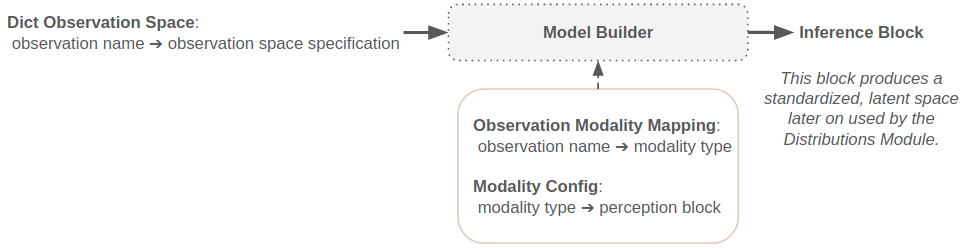
The Maze template model composer allows us to compose policy and value networks directly from an environment’s observation and action space specification according to a selected model template and a corresponding model config. The central part of a template model composer is the Model Builder holding an Inference Block template (architecture template), which is then instantiated according to the config.
Next, we will introduce the general working principles. However, you can of course directly jump to the examples below to see how to build a feed forward as well as a recurrent policy network using the ConcatModelBuilder or check out how to work with simple single observation and action environments.
List of Features¶
A template model supports the following features:
Works with dictionary observation spaces.
Maps individual observations to modalities via the Observation Modality Mapping.
Allows to individually assign Perception Blocks to modalities via the Modality Config.
Allows to pick architecture templates defining the underlying modal structure via Maze Model Builders.
Cooperates with the Distributions Module supporting customization of action and value outputs.
Allows to individually specify shared embedding keys for actor critic models; this enables shared embeddings between actor and critic.
Note
Maze so far does not support “end-to-end” default behaviour but instead provides config templates, which can be adopted to the respective needs. We opted for this route as complete defaults might lead to unintended and non-transparent results.
Model Builders (Architecture Templates)¶
This section lists and describes the available Model Builder architectures templates. Before we describe the builder instances in more detail we provide some information on the available block types:
Fixed: these blocks are fixed and are applied by the model builder per default.
Preset: these blocks are predefined for the respective model builder. They are basically place holders for which you can specify the perception blocks they should hold.
Custom: these blocks are introduced by the user for processing the respective observation modalities (types) such as features or images.
ConcatModelBuilder (Reference Documentation)
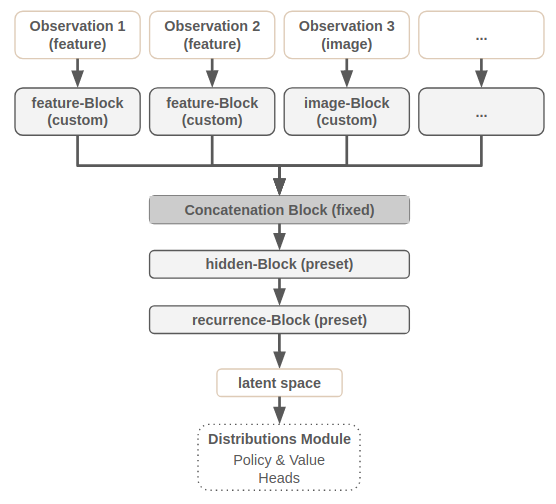
Model builder details:
Processes the individual observations with modality blocks (custom).
Joins the respective modality hidden representations via a concatenation block (fixed).
The resulting representation is then further processed by the hidden and recurrence block (preset).
Example 1: Feed Forward Models¶
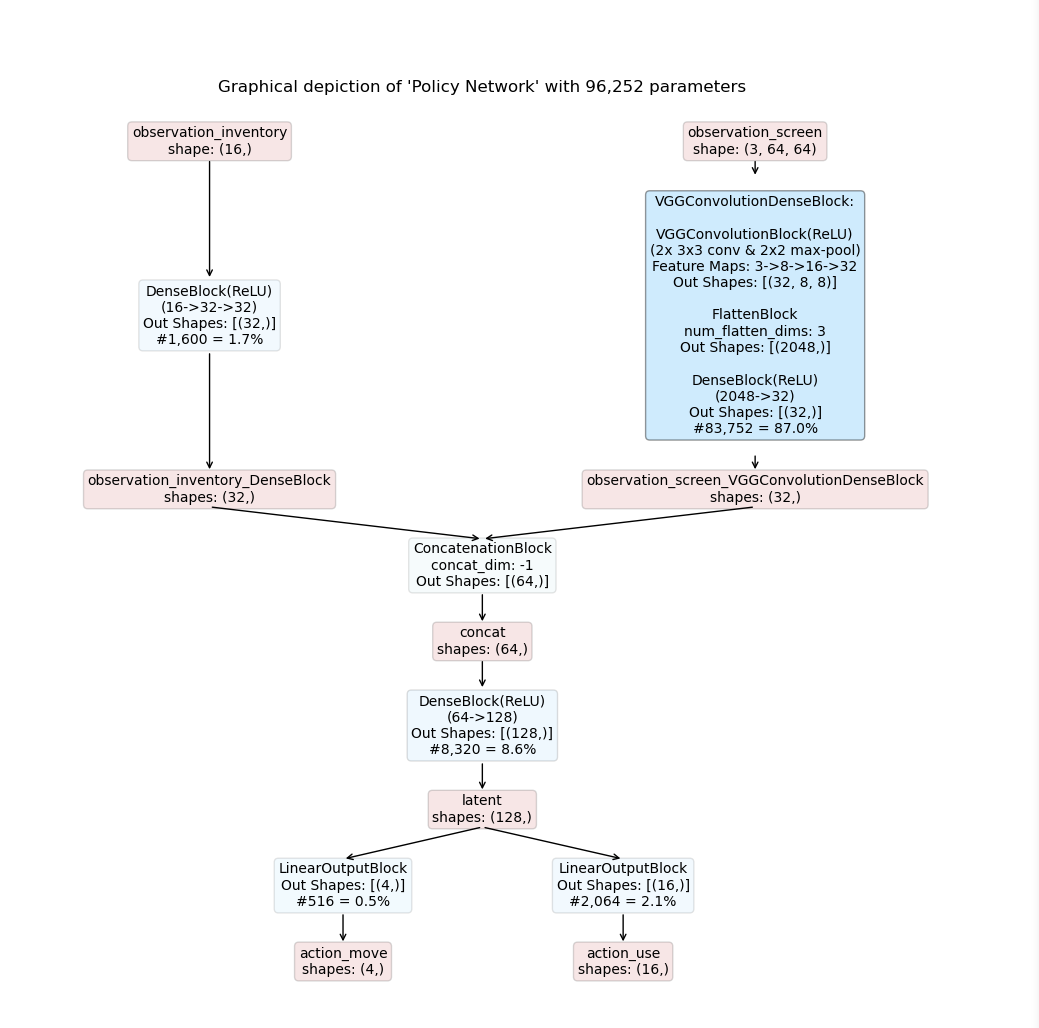
In this example we utilize the ConcatModelBuilder to compose a feed forward actor-critic model processing two observations for predicting two actions and one critic (value) output.
Observation Space:
observation_inventory : a 16-dimensional feature vector
observation_screen : a 64 x 64 RGB image
Action Space:
action_move : a categorical action with four options deciding to move [UP, DOWN, LEFT, RIGHT]
action_use : a 16-dimensional multi-binary action deciding which item to use from inventory
The model config is defined as:
# @package model
_target_: maze.perception.models.template_model_composer.TemplateModelComposer
# specify distribution mapping
# (here we use a default distribution mapping)
distribution_mapper_config: []
# specifies the architecture of default models
model_builder:
_target_: maze.perception.builders.ConcatModelBuilder
# Specify up to which keys the embedding should be shared between actor and critic
shared_embedding_keys: ~
# specifies the modality type of each observation
observation_modality_mapping:
observation_inventory: feature
observation_screen: image
# specifies with which block to process a modality
modality_config:
# modality processing
feature:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [32, 32]
non_lin: torch.nn.ReLU
image:
block_type: maze.perception.blocks.VGGConvolutionDenseBlock
block_params:
hidden_channels: [8, 16, 32]
hidden_units: [32]
non_lin: torch.nn.ReLU
# preserved keys for the model builder
hidden:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [128]
non_lin: torch.nn.ReLU
recurrence: {}
# select policy type
policy:
_target_: maze.perception.models.policies.ProbabilisticPolicyComposer
# select critic type
critic:
_target_: maze.perception.models.critics.StateCriticComposer
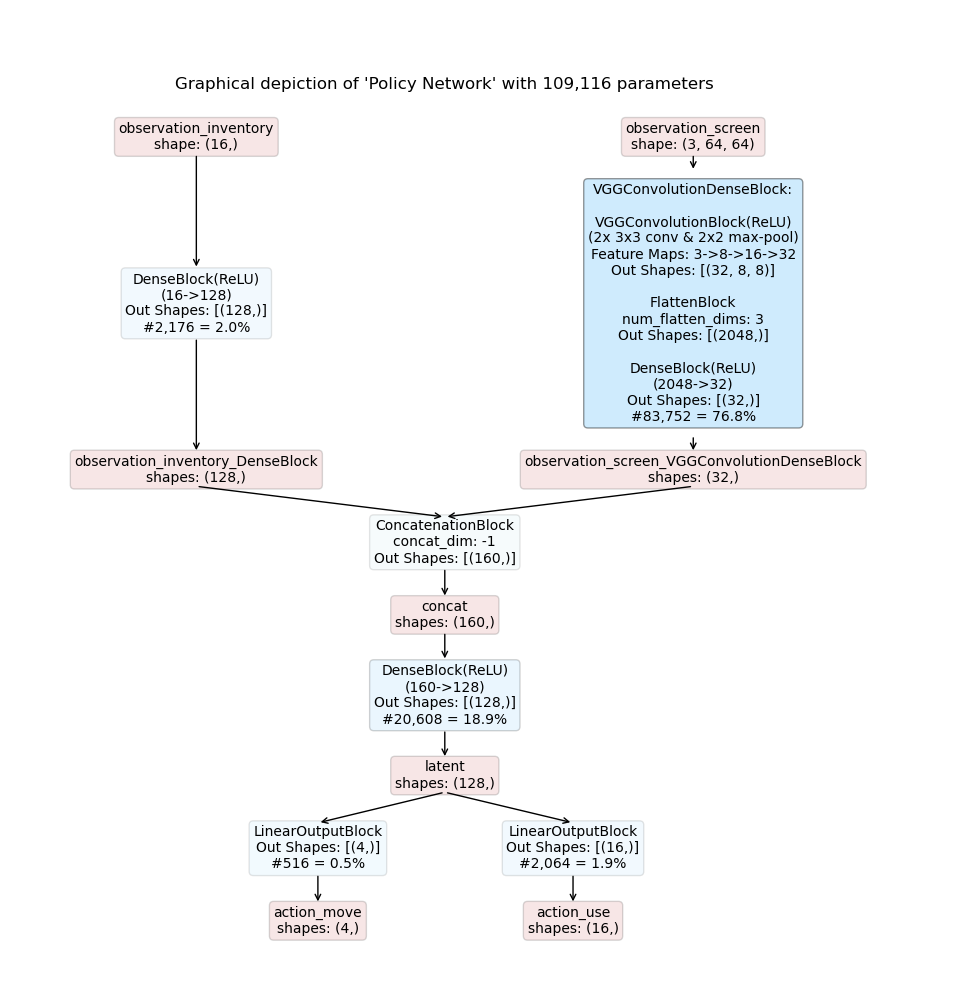
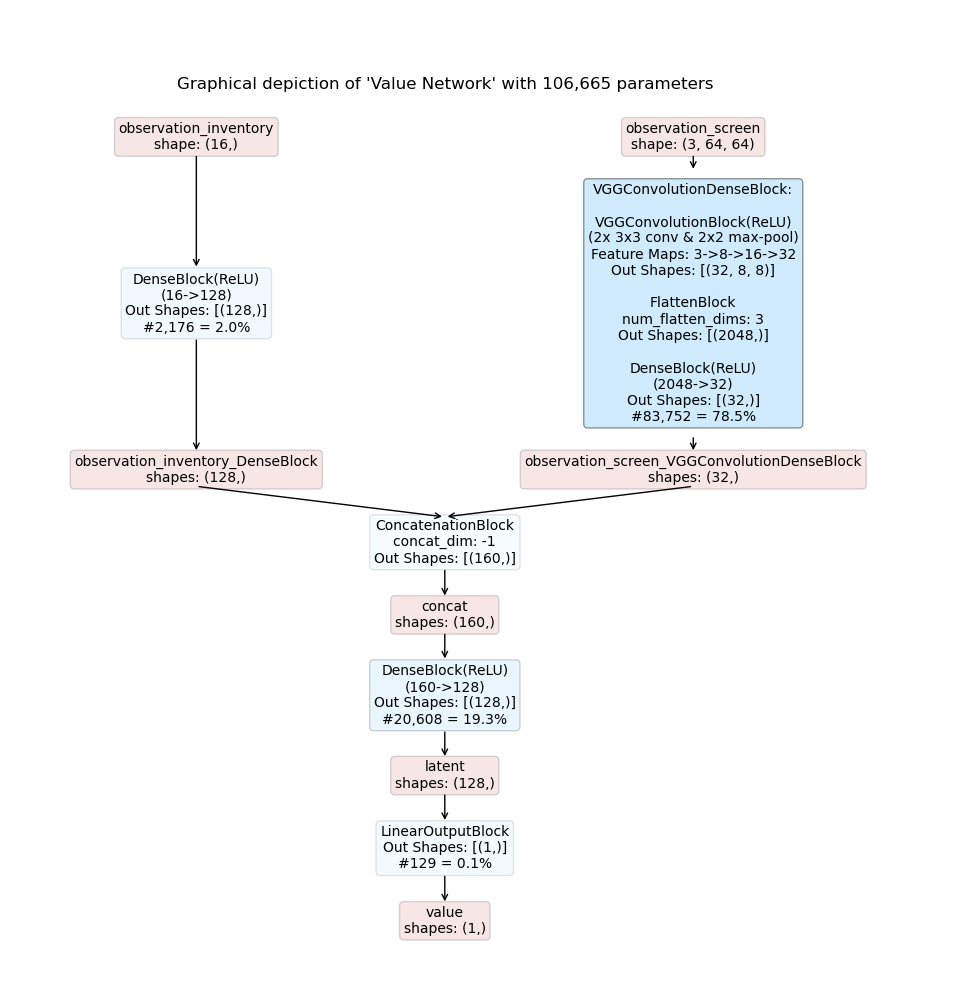
Details:
Models are composed by the Maze TemplateModelComposer.
No specific action space and probability distribution overrides are specified.
The model is based on the ConcatModelBuilder architecture template.
No shared embedding is used.
Observation observation_inventory is mapped to the user specified custom modality feature.
Observation observation_screen is mapped to the user specified custom modality image.
Modality Config:
Modalities of type feature are processed with a DenseBlock.
Modalities of type image are processed with a VGGConvolutionDenseBlock.
The concatenated joint spaces is processed with another DenseBlock.
No recurrence is employed.
The resulting inference graphs for an actor-critic model are shown below:
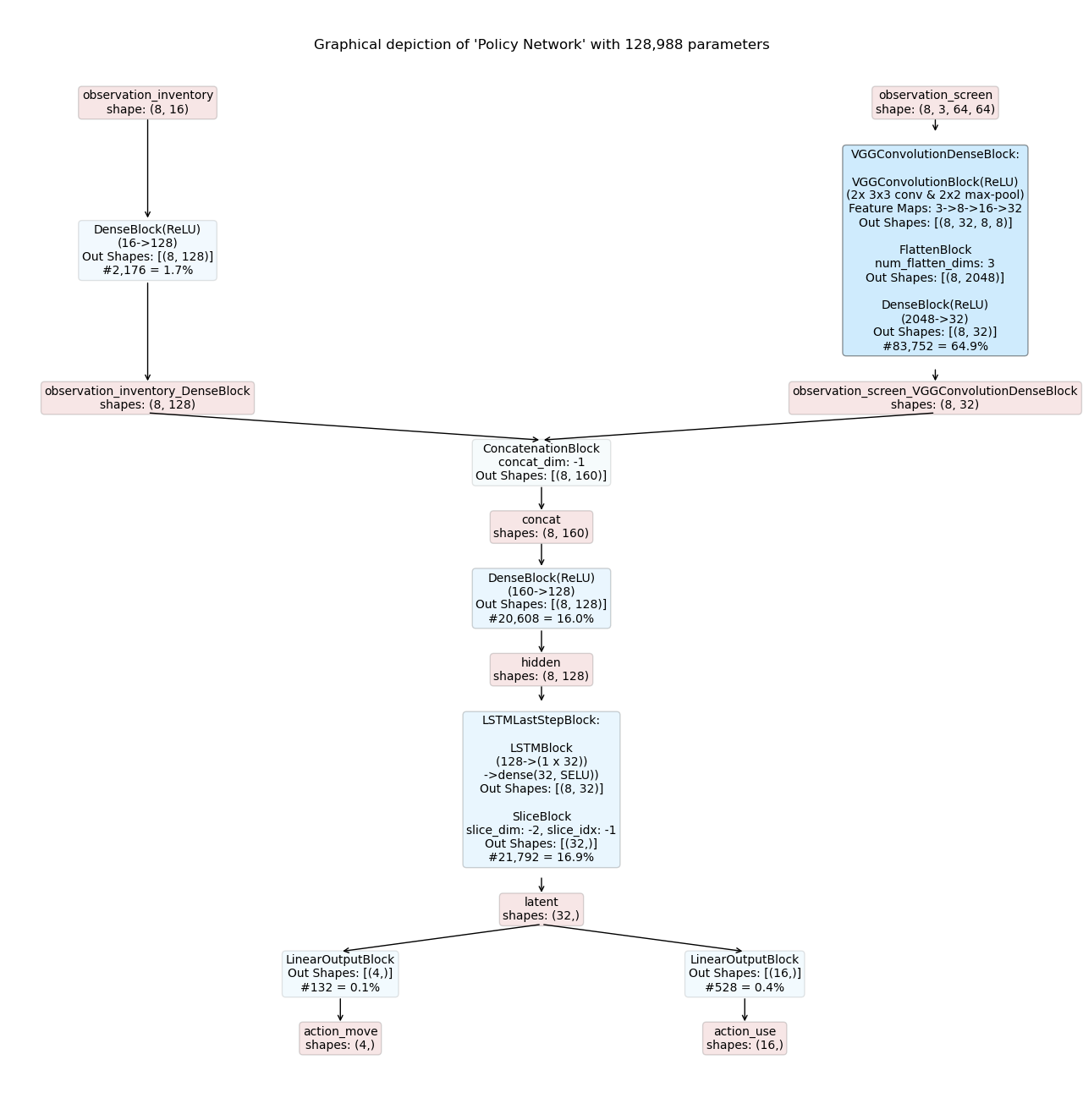
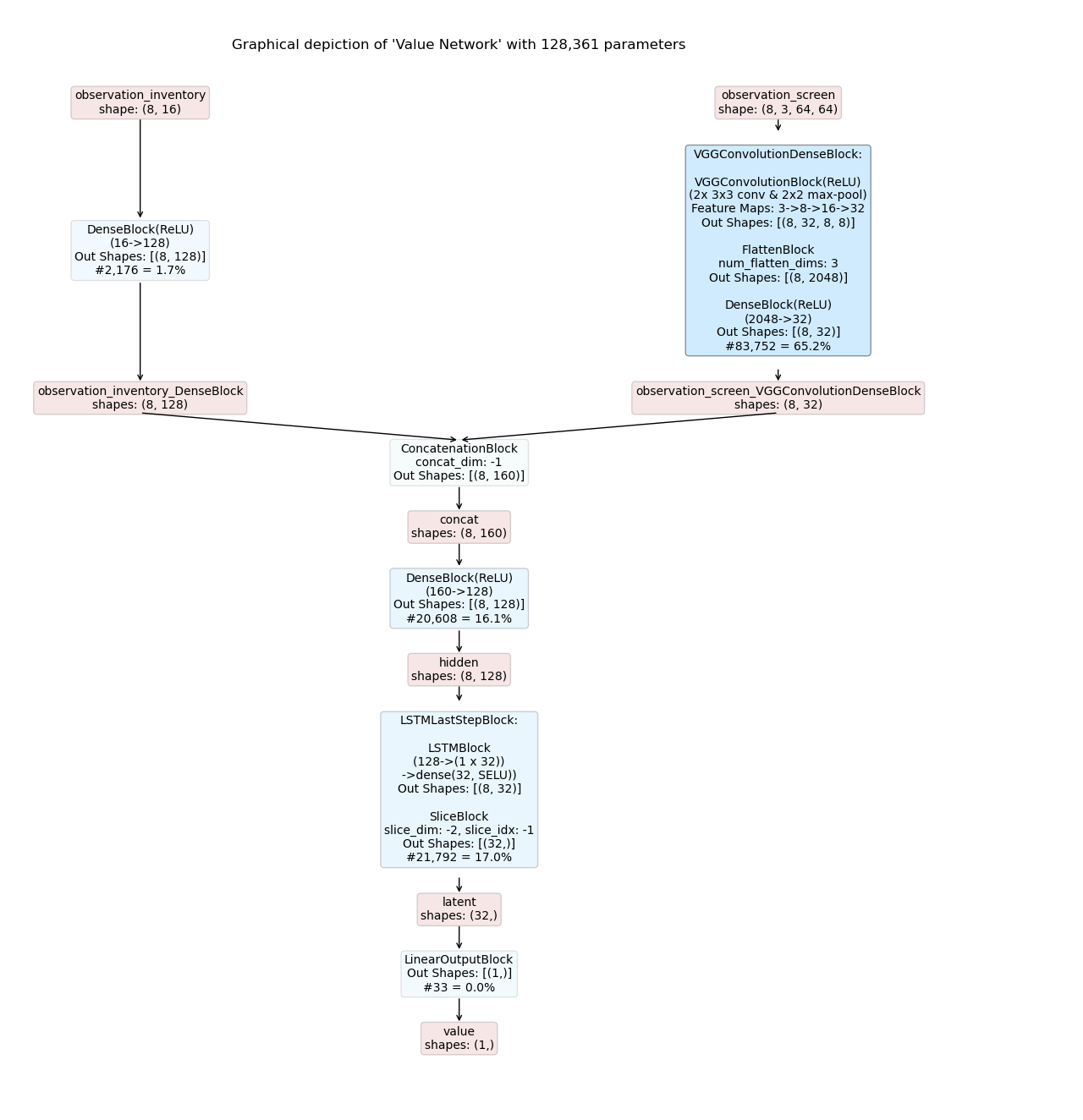
Example 2: Recurrent Models¶
In this example we utilize the ConcatModelBuilder to compose a recurrent actor-critic model for the the previous example.
# @package model
_target_: maze.perception.models.default_model_composer.DefaultModelComposer
# specify distribution mapping
# (here we use a default distribution mapping)
distribution_mapper_config: []
# specifies the architecture of default models
model_builder:
_target_: maze.perception.builders.ConcatModelBuilder
# Specify up to which keys the embedding should be shared between actor and critic
shared_embedding_keys: ~
# specifies the modality type of each observation
observation_modality_mapping:
observation_inventory: feature
observation_screen: image
# specifies with which block to process a modality
modality_config:
# modality processing
feature:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [32, 32]
non_lin: torch.nn.ReLU
image:
block_type: maze.perception.blocks.VGGConvolutionDenseBlock
block_params:
hidden_channels: [8, 16, 32]
hidden_units: [32]
non_lin: torch.nn.ReLU
# preserved keys for the model builder
hidden:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [128]
non_lin: torch.nn.ReLU
recurrence:
block_type: maze.perception.blocks.LSTMLastStepBlock
block_params:
hidden_size: 32
num_layers: 1
bidirectional: False
non_lin: torch.nn.SELU
# select policy type
policy:
_target_: maze.perception.models.policies.ProbabilisticPolicyComposer
# select critic type
critic:
_target_: maze.perception.models.critics.StateCriticComposer
Details:
The main part of the model is identical to the example above.
However, the example adds an additional recurrent block (LSTMLastStepBlock) considering not only the present but also the k previous time steps for its action and value predictions.
The resulting inference graphs for a recurrent actor-critic model are shown below:
Example 3: Single Observation and Action Models¶
Even though designed for more complex models which process multiple observations and prediction multiple actions at the same time you can of course also compose models for simpler use cases.
In this example we utilize the ConcatModelBuilder to compose an actor-critic model for OpenAI Gym’s CartPole Env. CartPole has an observation space with dimensionality four and a discrete action spaces with two options.
The model config is defined as:
# @package model
_target_: maze.perception.models.template_model_composer.TemplateModelComposer
# specify distribution mapping
# (here we use a default distribution mapping)
distribution_mapper_config: []
# specifies the architecture of default models
model_builder:
_target_: maze.perception.builders.ConcatModelBuilder
# Specify up to which keys the embedding should be shared between actor and critic
shared_embedding_keys: ~
# specifies the modality type of each observation
observation_modality_mapping:
observation: feature
# specifies with which block to process a modality
modality_config:
# modality processing
feature:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [32, 32]
non_lin: torch.nn.ReLU
# preserved keys for the model builder
hidden: {}
recurrence: {}
# select policy type
policy:
_target_: maze.perception.models.policies.ProbabilisticPolicyComposer
# select critic type
critic:
_target_: maze.perception.models.critics.StateCriticComposer
The resulting inference graphs for an actor-critic model are shown below:
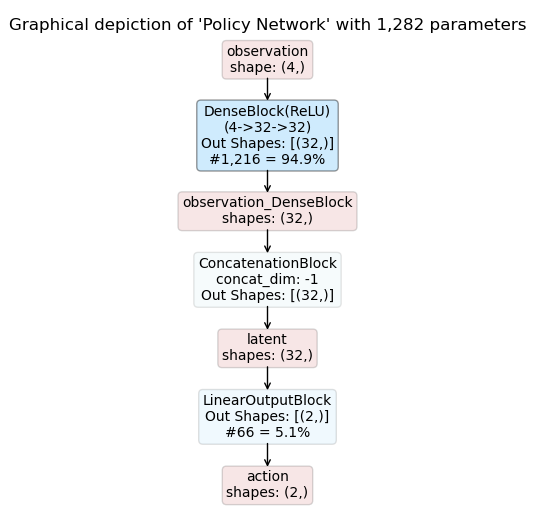
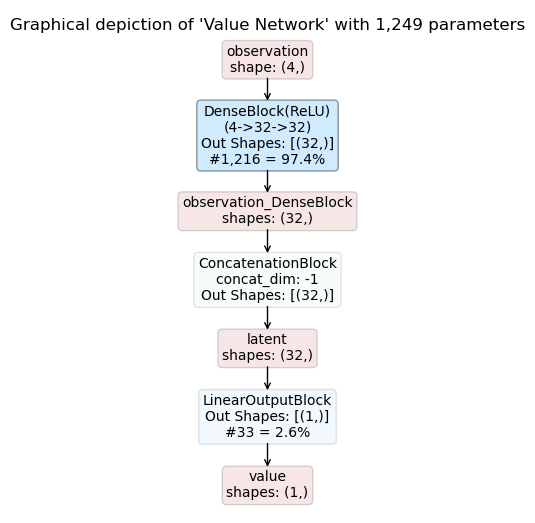
Details:
When there is only one observation, as for the present example, concatenation acts simply as an identity mapping of the previous output tensor (in this case observation_DenseBlock).
Example 4: Shared Embedding Feed Forward Model¶
In case of large dimensional input spaces it might sometimes be useful to share the embedding between the actor and critic network when training with an actor-critic algorithm. In this example we showcase how this can be done with the template model composer on the Example 1. Here everything stays the same, with one small exception: Now we specify the shared embedding key in the model builder config to be [‘latent’] as can be seen below.
The model config is defined as:
# @package model
_target_: maze.perception.models.template_model_composer.TemplateModelComposer
# specify distribution mapping
# (here we use a default distribution mapping)
distribution_mapper_config: []
# specifies the architecture of default models
model_builder:
_target_: maze.perception.builders.ConcatModelBuilder
# Specify up to which keys the embedding should be shared between actor and critic
shared_embedding_keys: ['latent']
# specifies the modality type of each observation
observation_modality_mapping:
observation_inventory: feature
observation_screen: image
# specifies with which block to process a modality
modality_config:
# modality processing
feature:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [32, 32]
non_lin: torch.nn.ReLU
image:
block_type: maze.perception.blocks.VGGConvolutionDenseBlock
block_params:
hidden_channels: [8, 16, 32]
hidden_units: [32]
non_lin: torch.nn.ReLU
# preserved keys for the model builder
hidden:
block_type: maze.perception.blocks.DenseBlock
block_params:
hidden_units: [128]
non_lin: torch.nn.ReLU
recurrence: {}
# select policy type
policy:
_target_: maze.perception.models.policies.ProbabilisticPolicyComposer
# select critic type
critic:
_target_: maze.perception.models.critics.StateCriticComposer
Now the output of the perception block ‘latent’ will be used as the input to the critic network. The resulting inference graphs for an actor-critic model are shown below:

Where to Go Next¶
You can read up on our general introduction to the Perception Module.
Here we explain how to define and work with custom models in case the template models are not sufficient.