Maze Trainers¶
Trainers are the central components of the Maze framework when it comes to optimizing policies using different RL algorithms. To be more specific, Trainers and TrainingRunners are responsible for the following tasks:
manage the model types (actor networks, state-critics, state-action-critic, …),
manage agent environment interaction and trajectory data generation,
compute the loss (specific to the algorithm used),
update the weights in order to decrease the loss and increase the performance,
collect and log training statistics,
manage model checkpoints and the training process (e.g., early stopping).
The figure below provides an overview of the currently supported Trainers.
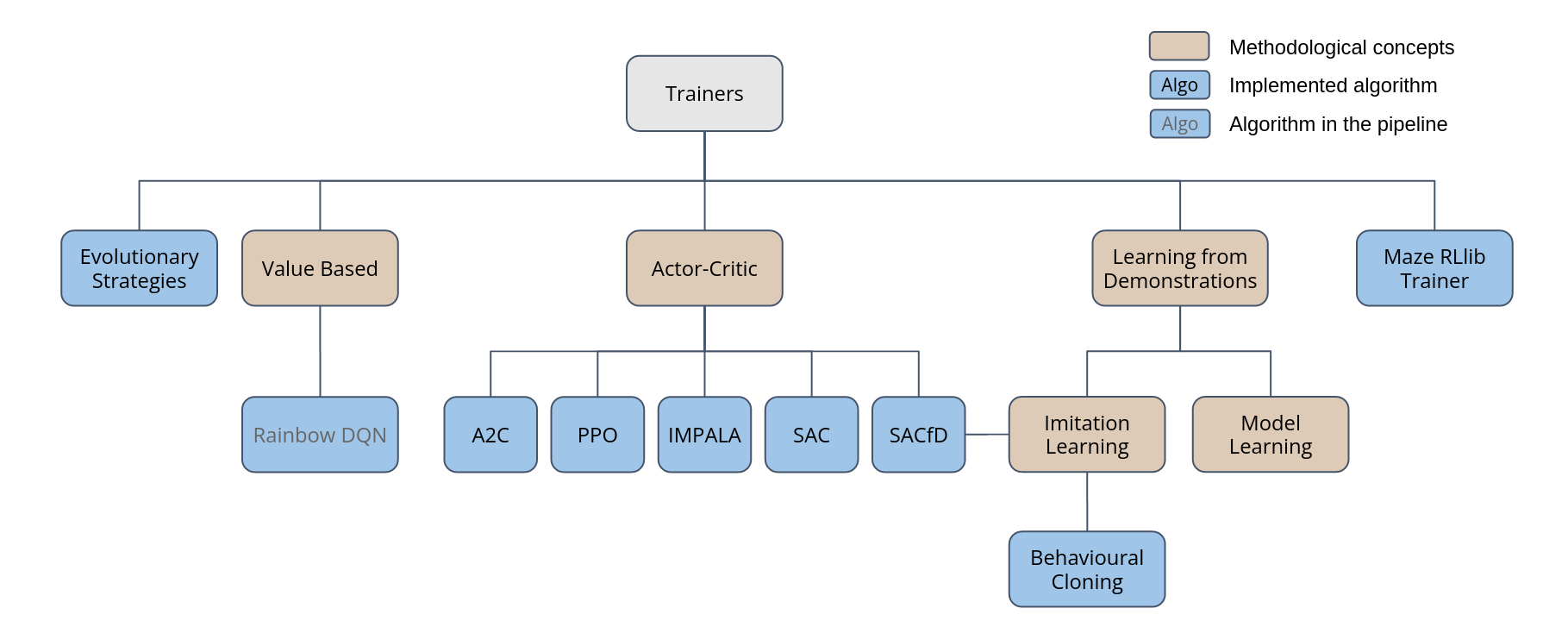
This page gives a general (high-level) overview of the Trainers and corresponding algorithms supported by the Maze framework. For more details especially on the implementation please refer to the API documentation on Trainers. For more details on the training workflow and how to start trainings using the Hydra config system please refer to the training section.
Supported Spaces¶
If not stated otherwise, Maze Trainers support dictionary spaces for both observations and actions.
If the environment you are working with does not yet interact via dictionary spaces
simply wrap it with the built-in
DictActionWrapper for actions
and
DictObservationWrapper for observations.
In case of standard Gym environments just use the GymMazeEnv.
Advantage Actor-Critic (A2C)¶
A2C is a synchronous version of the originally proposed Asynchronous Advantage Actor-Critic (A3C). As a policy gradient method it maintains a probabilistic policy, computing action selection probabilities, as well as a critic, predicting the state value function. By setting the number of rollout steps as well as the number of parallel environments one can control the batch size used for updating the policy and value function in each iteration.
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., & Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In International conference on machine learning (pp. 1928-1937).
Example
maze-run -cn conf_train env.name=CartPole-v1 algorithm=a2c model=vector_obs critic=template_state
Algorithm Parameters | A2CAlgorithmConfig
Default parameters (maze/conf/algorithm/a2c.yaml)
# @package algorithm
# number of epochs to train
n_epochs: 0
# number of updates per epoch
epoch_length: 25
# number of steps used for early stopping
patience: 15
# number of critic (value function) burn in epochs
critic_burn_in_epochs: 0
# Number of steps taken for each rollout
n_rollout_steps: 100
# learning rate
lr: 0.0005
# discounting factor
gamma: 0.98
# weight of policy loss
policy_loss_coef: 1.0
# weight of value loss
value_loss_coef: 0.5
# weight of entropy loss
entropy_coef: 0.00025
# The maximum allowed gradient norm during training
max_grad_norm: 0.0
# Either "cpu" or "cuda"
device: cpu
# bias vs variance trade of factor for Generalized Advantage Estimator (GAE)
gae_lambda: 1.0
# Number of seeds to be generated and used to seed the environment except when passing a list of explicit seeds"""
n_training_seeds: 100
# Rollout evaluator (used for best model selection)
rollout_evaluator:
_target_: maze.train.trainers.common.evaluators.rollout_evaluator.RolloutEvaluator
# Run evaluation in deterministic mode (argmax-policy)
deterministic: true
# Number of evaluation trials
n_episodes: 8
Runner Parameters | ACRunner
Default parameters (maze/conf/algorithm_runner/a2c-dev.yaml)
# @package runner
_target_: "maze.train.trainers.common.actor_critic.actor_critic_runners.ACDevRunner"
# model class used for policy and critic updates
trainer_class: maze.train.trainers.a2c.a2c_trainer.A2C
# Number of concurrently executed environments
concurrency: 2
# Number of concurrent evaluation envs
eval_concurrency: 1
Default parameters (maze/conf/algorithm_runner/a2c-local.yaml)
# @package runner
_target_: "maze.train.trainers.common.actor_critic.actor_critic_runners.ACLocalRunner"
# model class used for policy and critic updates
trainer_class: maze.train.trainers.a2c.a2c_trainer.A2C
# Number of concurrently executed environments
concurrency: 0
# Number of concurrent evaluation envs
eval_concurrency: 0
Proximal Policy Optimization (PPO)¶
The PPO algorithm belongs to the class of actor-critic style policy gradient methods. It optimizes a “surrogate” objective function adopted from trust region methods. As such, it alternates between generating trajectory data via agent rollouts from the environment and optimizing the objective function by means of a stochastic mini-batch gradient ascent.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
Example
maze-run -cn conf_train env.name=CartPole-v1 algorithm=ppo model=vector_obs critic=template_state
Algorithm Parameters | PPOAlgorithmConfig
Default parameters (maze/conf/algorithm/ppo.yaml)
# @package algorithm
# number of epochs to train
n_epochs: 0
# number of updates per epoch
epoch_length: 25
# number of steps used for early stopping
patience: 15
# number of critic (value function) burn in epochs
critic_burn_in_epochs: 0
# Number of steps taken for each rollout
n_rollout_steps: 100
# learning rate
lr: 0.00025
# discounting factor
gamma: 0.98
# bias vs variance trade of factor for Generalized Advantage Estimator (GAE)
gae_lambda: 1.0
# weight of policy loss
policy_loss_coef: 1.0
# weight of value loss
value_loss_coef: 0.5
# weight of entropy loss
entropy_coef: 0.00025
# The maximum allowed gradient norm during training
max_grad_norm: 0.0
# Either "cpu" or "cuda"
device: cpu
# The batch size used for policy and value updates
batch_size: 100
# Number of epochs for policy and value optimization
n_optimization_epochs: 4
# Clipping parameter of surrogate loss
clip_range: 0.2
# Number of seeds to be generated and used to seed the environment except when passing a list of explicit seeds"""
n_training_seeds: 100
# Rollout evaluator (used for best model selection)
rollout_evaluator:
_target_: maze.train.trainers.common.evaluators.rollout_evaluator.RolloutEvaluator
# Run evaluation in deterministic mode (argmax-policy)
deterministic: true
# Number of evaluation trials
n_episodes: 8
Runner Parameters | ACRunner
Default parameters (maze/conf/algorithm_runner/ppo-dev.yaml)
# @package runner
_target_: "maze.train.trainers.common.actor_critic.actor_critic_runners.ACDevRunner"
# model class used for policy and critic updates
trainer_class: maze.train.trainers.ppo.ppo_trainer.PPO
# Number of concurrently executed environments
concurrency: 2
# Number of concurrent evaluation envs
eval_concurrency: 1
Default parameters (maze/conf/algorithm_runner/ppo-local.yaml)
# @package runner
_target_: "maze.train.trainers.common.actor_critic.actor_critic_runners.ACLocalRunner"
# model class used for policy and critic updates
trainer_class: maze.train.trainers.ppo.ppo_trainer.PPO
# Number of concurrently executed environments
concurrency: 0
# Number of concurrent evaluation envs
eval_concurrency: 0
Importance Weighted Actor-Learner Architecture (IMPALA)¶
IMPALA is a RL algorithm able to scale to a very large number of machines. Multiple workers collect trajectories (sequences of states, actions and rewards), which are communicated to a learner responsible for updating the policy by utilizing stochastic mini-batch gradient decent and the proposed V-trace correction algorithm. By decoupling rollouts (interactions with the environment) and policy updates the algorithm is considered off-policy and asynchronous, making it very suitable for compute-intense environments.
Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., Dunning, I., Legg, S., & Kavukcuoglu, K. (2018). Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. arXiv preprint arXiv:1802.01561.
Example
maze-run -cn conf_train env.name=CartPole-v1 algorithm=impala model=vector_obs critic=template_state
Algorithm Parameters | ImpalaAlgorithmConfig
Default parameters (maze/conf/algorithm/impala.yaml)
# @package algorithm
# Common Actor critic parameters
# number of epochs to train
n_epochs: 0
# number of updates per epoch
epoch_length: 25
# number of steps used for early stopping
patience: 15
# number of critic (value function) burn in epochs
critic_burn_in_epochs: 0
# number of rolloutstep of each epoch substep
n_rollout_steps: 100
# learning rate
lr: 0.0005
# discount factor
gamma: 0.98
# coefficient of the policy used in the loss calculation
policy_loss_coef: 1.0
# coefficient of the value used in the loss calculation
value_loss_coef: 0.5
# coefficient of the entropy used in the loss calculation
entropy_coef: 0.01
# max grad norm for gradient clipping, ignored if value==0
max_grad_norm: 0
# Device of the learner (either cpu or cuda)
# Note that the actors collecting rollouts are always run on CPU.
device: "cpu"
# Impala specific events ----------------------
# this factor multiplied by the actor_batch_size gives the size of the queue for
# the agents output collected by the learner. Therefor if the all rollouts computed can be at most
# (queue_out_of_sync_factor + num_agents/actor_batch_size) out of sync with learner policy
queue_out_of_sync_factor: 1
# number of actors to combine to one batch
actors_batch_size: 8
# number of actors to be run
num_actors: 8
# A scalar float32 tensor with the clipping threshold for importance weights
# (rho) when calculating the baseline targets (vs). rho^bar in the paper. If None, no clipping is applied.
vtrace_clip_rho_threshold: 1.0
# A scalar float32 tensor with the clipping threshold on rho_s in
# \rho_s \delta log \pi(a|x) (r + \gamma v_{s+1} - V(x_sfrom_importance_weights)). If None, no clipping is
# applied.
vtrace_clip_pg_rho_threshold: 1.0
# Number of seeds to be generated and used to seed the environment except when passing a list of explicit seeds"""
n_training_seeds: 100
# Rollout evaluator (used for best model selection)
rollout_evaluator:
_target_: maze.train.trainers.common.evaluators.rollout_evaluator.RolloutEvaluator
# Run evaluation in deterministic mode (argmax-policy)
deterministic: true
# Number of evaluation trials
n_episodes: 8
Runner Parameters | ImpalaRunner
Default parameters (maze/conf/algorithm_runner/impala-dev.yaml)
# @package runner
_target_: "maze.train.trainers.impala.impala_runners.ImpalaDevRunner"
# Number of concurrent evaluation envs
eval_concurrency: 1
Default parameters (maze/conf/algorithm_runner/impala-local.yaml)
# @package runner
_target_: "maze.train.trainers.impala.impala_runners.ImpalaLocalRunner"
# type of startmethod used for multiprocessing: 'forkserver', 'spawn', 'fork', 'dummy'
start_method: forkserver
# Number of concurrent evaluation envs
eval_concurrency: 0
Soft Actor-Critic (from Demonstrations) (SAC, SACfD)¶
An off-policy actor-critic algorithm based on the maximum entropy reinforcement learning framework with the goal of maximizing expected reward while at the same time maximizing entropy. SAC exhibits high sample efficiency, is stable across different random seeds, and achieves competitive performance especially for continuous control tasks. In contrast to A2C, PPO and IMPALA it utilizes a stochastic state-action critic.
Additionally, our implementation allows to initialize the replay buffer from existing demonstrations (e.g., rollouts) instead of sampling the initial transitions with the given sampling policy (per default random). This variant is called Soft Actor-Critic from Demonstrations.
Haarnoja, T., Zhou, A., Abbeel, P., Levine, S. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv preprint arXiv:1801.01290., Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., … & Levine, S. (2018). Soft Actor-Critic Algorithms and Applications. arXiv preprint arXiv:1812.05905., Christodoulou, P. (2019). Soft actor-critic for discrete action settings. arXiv preprint arXiv:1910.07207.
Example SAC
maze-run -cn conf_train env.name=Pendulum-v0 algorithm=sac model=vector_obs critic=template_state_action
Example SACfD
maze-run env.name=LunarLander-v3 policy=lunar_lander_heuristics runner.n_episodes=1000
maze-run -cn conf_train env.name=LunarLander-v3 algorithm=sacfd model=flatten_concat critic=flatten_concat_state_action runner.initial_demonstration_trajectories.input_data=<absolute_experiment_path>/trajectory_data
Algorithm Parameters | SACAlgorithmConfig
Default parameters (maze/conf/algorithm/sac.yaml)
# @package algorithm
# Number of steps taken for each rollout
n_rollout_steps: 1
# Learning rate
lr: 0.001
# The entropy coefficient to use in the loss computation (called alpha in org paper)
entropy_coef: 0.2
# Discounting factor
gamma: 0.99
# The maximum allowed gradient norm during training
max_grad_norm: 0.0
# Number of actors to combine to one batch
batch_size: 100
# Number of batches to update on in each iteration
num_batches_per_iter: 1
# Number of actors to be run
num_actors: 1
# Parameter weighting the soft update of the target network
tau: 0.005
# Specify in what intervals to update the target networks
target_update_interval: 1
# Either "cpu" or "cuda"
device: cpu
# Specify whether to learn the entropy coefficient or rather use the default one (entropy_coef) [called alpha in paper]
entropy_tuning: true
# Specify an optional multiplier for the target entropy. This value is multiplied with the default target entropy
# computation (this is called alpha tuning in the org paper):
# discrete spaces: target_entropy = target_entropy_multiplier * ( - 0.98 * (-log (1 / |A|))
# continues spaces: target_entropy = target_entropy_multiplier * (- dim(A)) (e.g., -6 for HalfCheetah-v1)
target_entropy_multiplier: 1.0
# Learning rate for entropy tuning
entropy_coef_lr: 0.0007
# The size of the replay buffer
replay_buffer_size: 1000000
# The initial buffer size, where transaction are sampled with the initial sampling policy
initial_buffer_size: 10000
# The policy used to initially fill the replay buffer
initial_sampling_policy:
_target_: maze.core.agent.random_policy.RandomPolicy
# Number of rollouts collected from the actor in each iteration
rollouts_per_iteration: 1
# Specify whether all computed rollouts should be split into transitions before processing them
split_rollouts_into_transitions: true
# Number of epochs to train
n_epochs: 0
# Number of updates per epoch
epoch_length: 100
# Number of steps used for early stopping
patience: 50
# Rollout evaluator (used for best model selection)
rollout_evaluator:
_target_: maze.train.trainers.common.evaluators.rollout_evaluator.RolloutEvaluator
# Run evaluation in deterministic mode (argmax-policy)
deterministic: true
# Number of evaluation trials
n_episodes: 8
Runner Parameters SAC | SACRunner
Default parameters (maze/conf/algorithm_runner/sac-dev.yaml)
# @package runner
_target_: "maze.train.trainers.sac.sac_runners.SACDevRunner"
# Number of concurrent evaluation envs
eval_concurrency: 1
# Specify the Dataset class used to load the trajectory data for training, otherwise the initial replay buffer is
# sampled with the provided initial_sampling_policy
initial_demonstration_trajectories: ~
Default parameters (maze/conf/algorithm_runner/sac-local.yaml)
# @package runner
_target_: "maze.train.trainers.sac.sac_runners.SACDevRunner"
# Number of concurrent evaluation envs
eval_concurrency: 0
# Specify the Dataset class used to load the trajectory data for training, otherwise the initial replay buffer is
# sampled with the provided initial_sampling_policy
initial_demonstration_trajectories: ~
Runner Parameters SACfD | SACRunner
Default parameters (maze/conf/algorithm_runner/sacfd-dev.yaml)
# @package runner
_target_: "maze.train.trainers.sac.sac_runners.SACDevRunner"
# Number of concurrent evaluation envs
eval_concurrency: 1
# Specify the dataset class used to load the trajectory data for training, otherwise the initial replay buffer is
# sampled with the provided initial_sampling_policy
initial_demonstration_trajectories:
_target_: maze.core.trajectory_recording.datasets.in_memory_dataset.InMemoryDataset
input_data: trajectory_data
n_workers: 1
deserialize_in_main_thread: false
trajectory_processor:
_target_: maze.core.trajectory_recording.datasets.trajectory_processor.IdentityWithNextObservationTrajectoryProcessor
Default parameters (maze/conf/algorithm_runner/sacfd-local.yaml)
# @package runner
_target_: "maze.train.trainers.sac.sac_runners.SACDevRunner"
# Number of concurrent evaluation envs
eval_concurrency: 0
# Specify the dataset class used to load the trajectory data for training, otherwise the initial replay buffer is
# sampled with the provided initial_sampling_policy
initial_demonstration_trajectories:
_target_: maze.core.trajectory_recording.datasets.in_memory_dataset.InMemoryDataset
input_data: trajectory_data
n_workers: 5
deserialize_in_main_thread: false
trajectory_processor:
_target_: maze.core.trajectory_recording.datasets.trajectory_processor.IdentityWithNextObservationTrajectoryProcessor
Behavioural Cloning (BC)¶
Behavioural cloning is a simple imitation learning algorithm, that infers the behaviour of a “hidden” policy by imitating the actions produced for a given observation in a supervised learning setting. As such, it requires a set of training (example) trajectories collected prior to training.
Hussein, A., Gaber, M. M., Elyan, E., & Jayne, C. (2017). Imitation learning: A survey of learning methods. ACM Computing Surveys (CSUR), 50(2), 1-35.
Example: Imitation Learning and Fine-Tuning
Algorithm Parameters | BCAlgorithmConfig
Default parameters (maze/conf/algorithm_runner/bc.yaml)
# @package algorithm
# Number of epochs to train for
n_epochs: 1000
# Optimizer used to update the policy
optimizer:
_target_: torch.optim.Adam
lr: 0.001
# Device to train on
device: cuda
# Batch size
batch_size: 100
# Number of iterations after which to run evaluation (in addition to evaluations at the end of
# each epoch, which are run automatically). If set to None, evaluations will run on epoch end only.
eval_every_k_iterations: 500
# Percentage of the data used for validation.
validation_percentage: 20
# Number of episodes to run during each evaluation rollout (set to 0 to evaluate using validation only)
n_eval_episodes: 8
# Number of epochs to elapse before evaluating the policy
eval_start_epoch: 0
# Number of epochs to elapse between two policy evaluations
eval_frequency: 1
# Entropy coefficient for policy optimization.
entropy_coef: 0.0
# Whether to dump evaluation stats to file.
dump_events_to_file: False
# Whether to show substep specific stats.
log_substep_events: False
# The loss to be used for the behavioural cloning.
loss:
_target_: maze.train.trainers.imitation.bc_loss.BCLoss
Runner Parameters | BCRunner
Default parameters (maze/conf/algorithm_runner/bc-dev.yaml)
# @package runner
_target_: maze.train.trainers.imitation.bc_runners.BCDevRunner
# Number of concurrent evaluation envs
eval_concurrency: 1
# Specify the Dataset class used to load the trajectory data for training
dataset:
_target_: maze.core.trajectory_recording.datasets.in_memory_dataset.InMemoryDataset
input_data: trajectory_data
n_workers: 1
deserialize_in_main_thread: false
trajectory_processor:
_target_: maze.core.trajectory_recording.datasets.trajectory_processor.IdentityTrajectoryProcessor
Default parameters (maze/conf/algorithm_runner/bc-local.yaml)
# @package runner
_target_: maze.train.trainers.imitation.bc_runners.BCLocalRunner
# Number of concurrent evaluation envs
eval_concurrency: 1
# Specify the Dataset class used to load the trajectory data for training
dataset:
_target_: maze.core.trajectory_recording.datasets.in_memory_dataset.InMemoryDataset
input_data: trajectory_data
n_workers: 5
deserialize_in_main_thread: false
trajectory_processor:
_target_: maze.core.trajectory_recording.datasets.trajectory_processor.IdentityTrajectoryProcessor
Evolutionary Strategies (ES)¶
Evolutionary strategies is a black box optimization algorithm that utilizes direct policy search and can be very efficiently parallelized. Advantages of this methods include being invariant to action frequencies as well as delayed rewards. Further, it shows tolerance for extremely long time horizons, since it does need to compute or approximate a temporally discounted value function. However, it is considered less sample efficient then actual RL algorithms.
Salimans, T., Ho, J., Chen, X., Sidor, S., & Sutskever, I. (2017). Evolution strategies as a scalable alternative to reinforcement learning. arXiv preprint arXiv:1703.03864.
Example
maze-run -cn conf_train env.name=CartPole-v1 algorithm=es model=vector_obs
Algorithm Parameters | ESAlgorithmConfig
Default parameters (maze/conf/algorithm_runner/es.yaml)
# @package algorithm
# Minimum number of episode rollouts per training iteration (=epoch)
n_rollouts_per_update: 10
# Minimum number of cumulative env steps per training iteration (=epoch).
# The training iteration is only finished, once the given number of episodes
# AND the given number of steps has been reached. One of the two parameters
# can be set to 0.
n_timesteps_per_update: 0
# The number of epochs to train before termination. Pass 0 to train indefinitely
n_epochs: 0
# Limit the episode rollouts to a maximum number of steps. Set to 0 to disable this option.
max_steps: 0
# The optimizer to use to update the policy based on the sampled gradient.
optimizer:
_target_: maze.train.trainers.es.optimizers.adam.Adam
step_size: 0.01
# L2 weight regularization coefficient.
l2_penalty: 0.005
# The scaling factor of the random noise applied during training.
noise_stddev: 0.02
# Support for simulation logic or heuristics on top of a TorchPolicy.
policy_wrapper: ~
Runner Parameters | ESMasterRunner
Default parameters (maze/conf/algorithm_runner/es-dev.yaml)
# @package runner
_target_: "maze.train.trainers.es.ESDevRunner"
# Fixed number of evaluation runs per epoch.
n_eval_rollouts: 10
# Number of float values in the deterministically generated pseudo-random table
shared_noise_table_size: 100000000
Default parameters (maze/conf/algorithm_runner/es-local.yaml)
# @package runner
_target_: "maze.train.trainers.es.ESLocalRunner"
# Number of worker processes to spawn for training
n_train_workers: 4
# Number of worker processes to spawn for evaluation
n_eval_workers: 1
# Number of float values in the deterministically generated pseudo-random table
shared_noise_table_size: 250000000
# Type of start method used for multiprocessing: 'forkserver', 'spawn', or 'fork'
start_method: forkserver
Where to Go Next¶
You can read up on our general introduction to the Maze Training Workflow.
To build and use custom Maze models please refer to Maze Perception Module.
You can also look up the supported Action Spaces and Distributions Module.