Tensorboard and Command Line Logging¶
This page gives a brief overview of the Tensorboard and command line logging facilities of Maze. We will show examples based on the cutting-2D Maze environment to make things a bit more interesting.
To understand the underlying concepts we recommend to read the sections on event and KPI logging as well as on the Maze event system.
Tensorboard Logging¶
To watch the training progress with Tensorboard start it by running:
tensorboard --logdir outputs/
and view it with your browser at http://localhost:6006/.
You will get an output similar to the one shown in the image below.
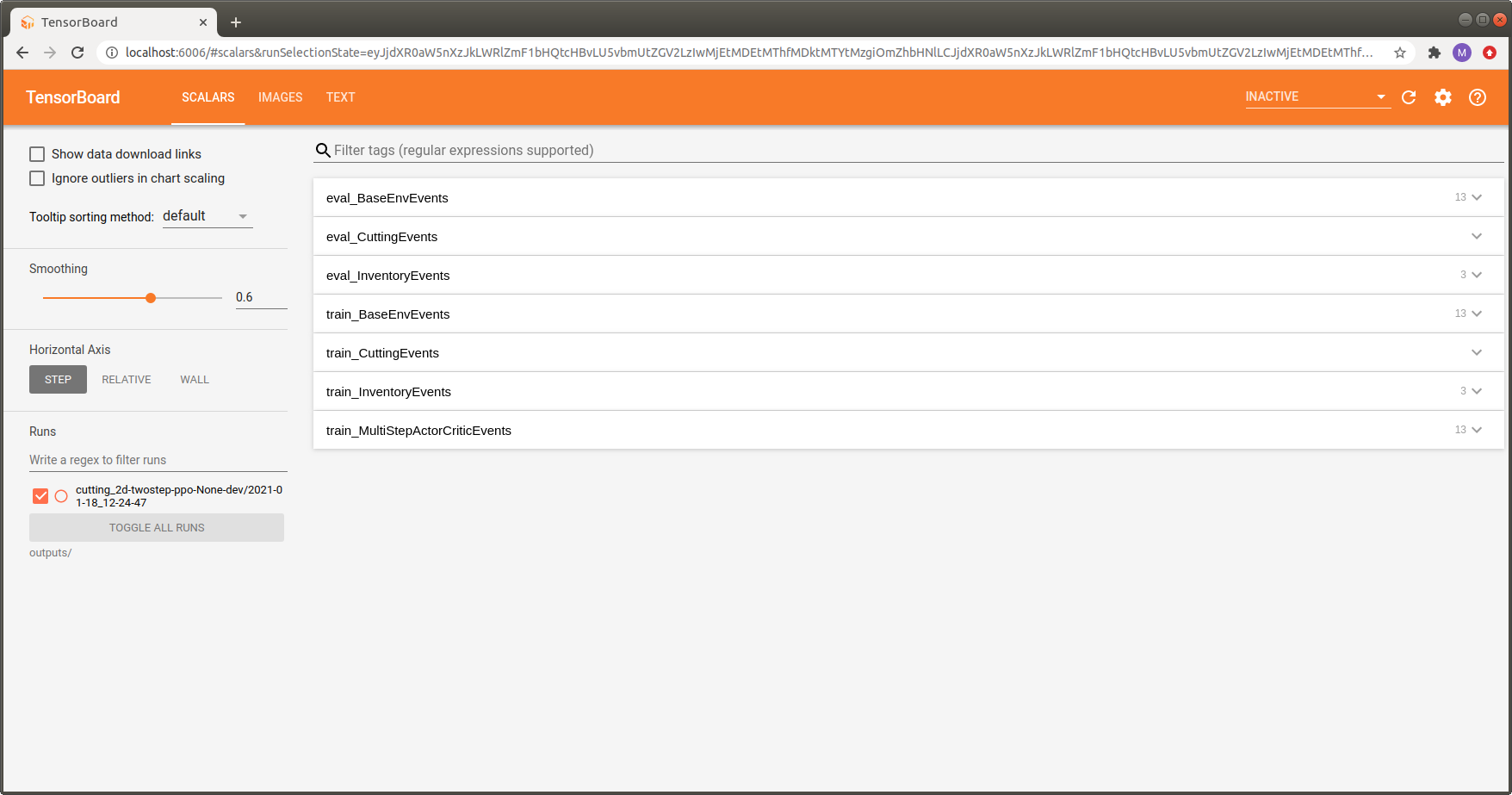
To keep everything organized and avoid having to browse through tons of pages we group the contained items into semantically connected sections:
Since Maze allows you to use different environments for training and evaluation, each logging section has a train_ or eval_ prefix to show if the corresponding stats were logged as part of the training or the evaluation environment.
The BaseEnvEvents sections (i.e., eval_BaseEnvEvents and train_BaseEnvEvents contain general statistics such as rewards or step counts. This section is always present, independent of the environment used.
Other sections are specific to the environment used. In the example above, these are the CuttingEvents and the InventoryEvents.
In addition, we get one additional section containing stats of the trainer used, called train_NameOfTrainerEvents. It contains statistics such as policy loss, gradient norm or value loss. This section is not present for the evaluation environment.
The gallery below shows some additional useful examples and features of the Maze Tensorboard log (click the images to display them in large).
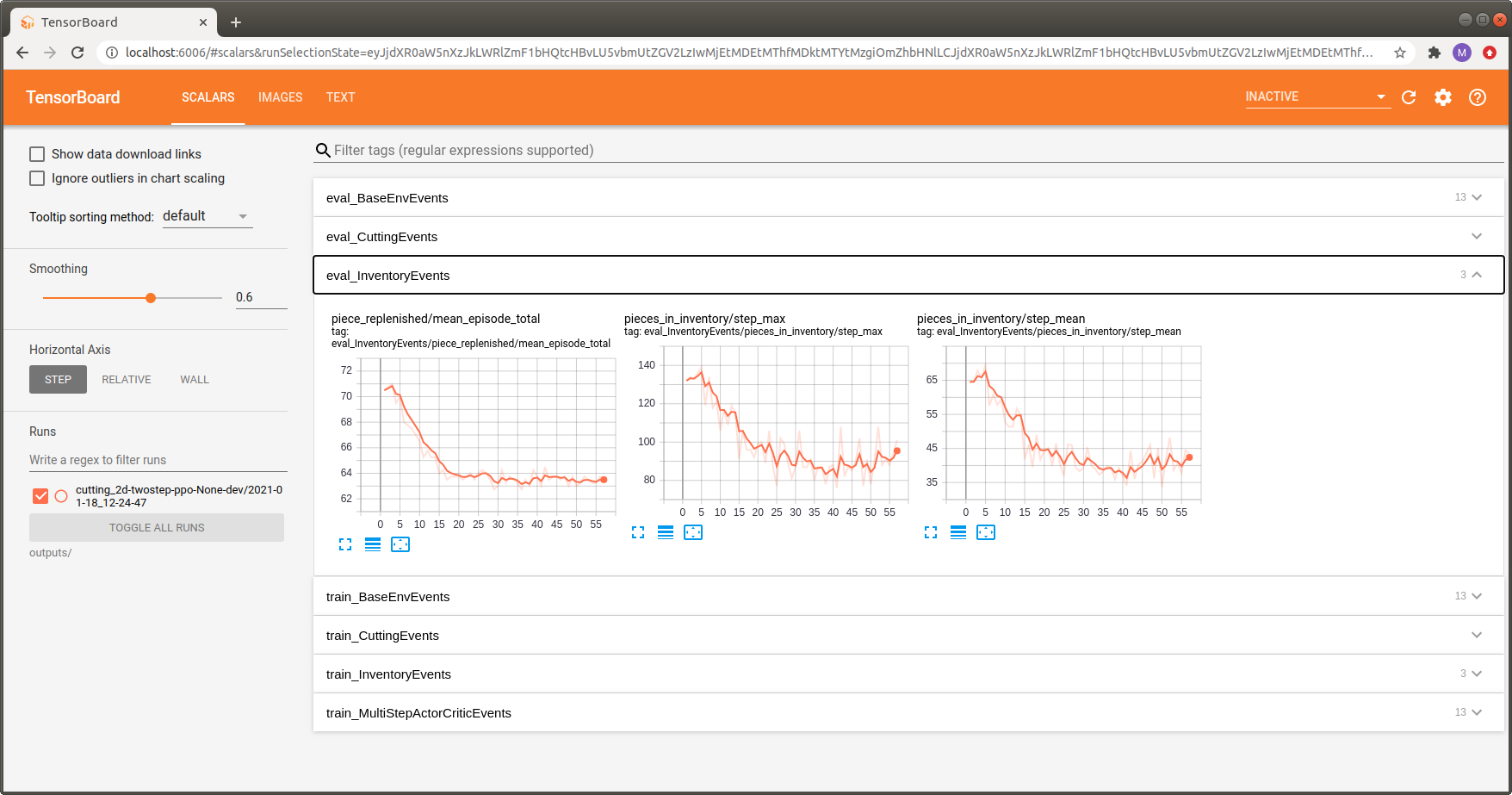
Logging of component specific events
in the SCALARS tab.
(Useful for understanding the environment)
|
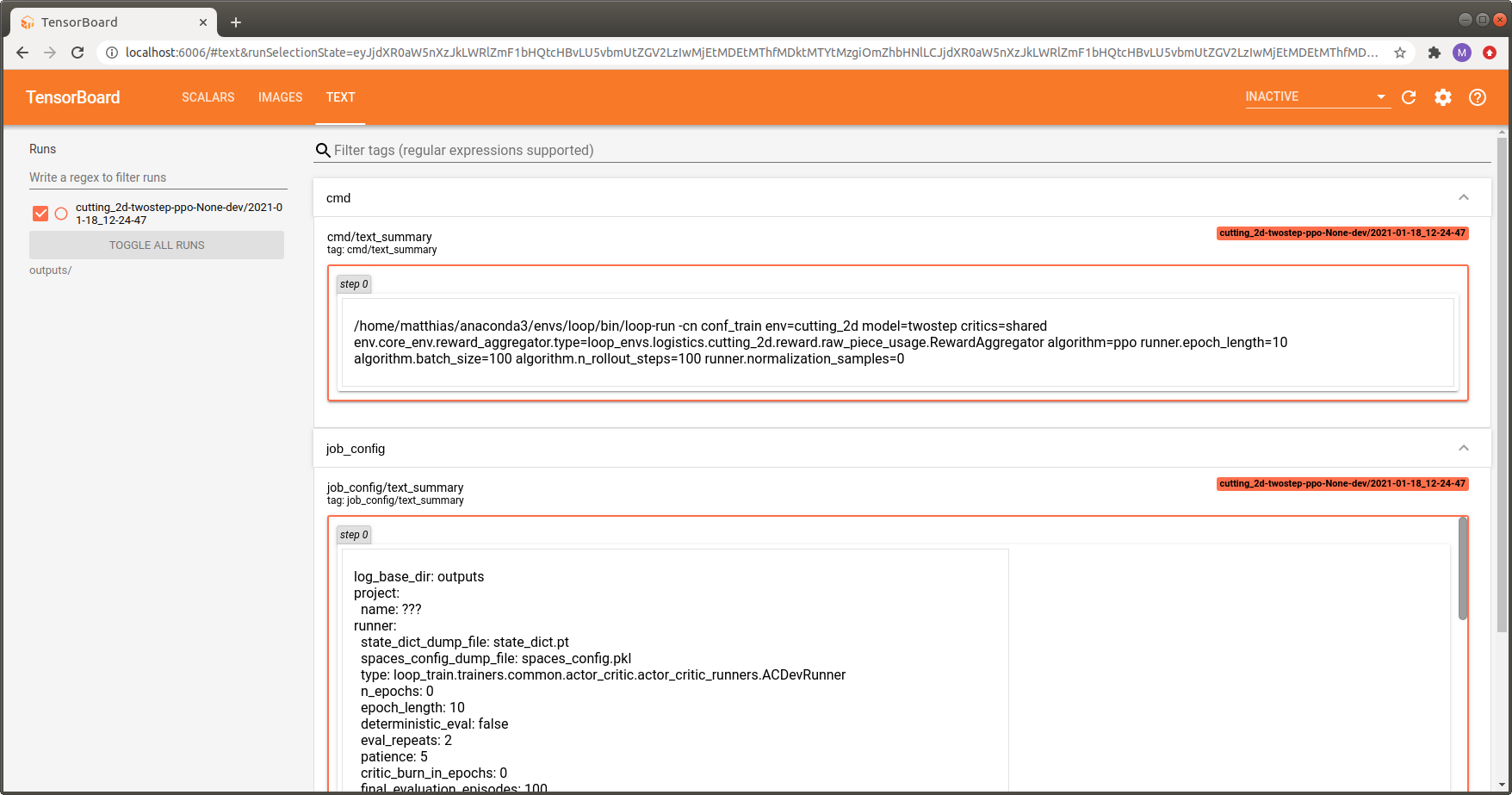
Logging of the training command and the complete
hydra job config in the TEXT tab.
(Useful for reproducing experiments)
|
|
|
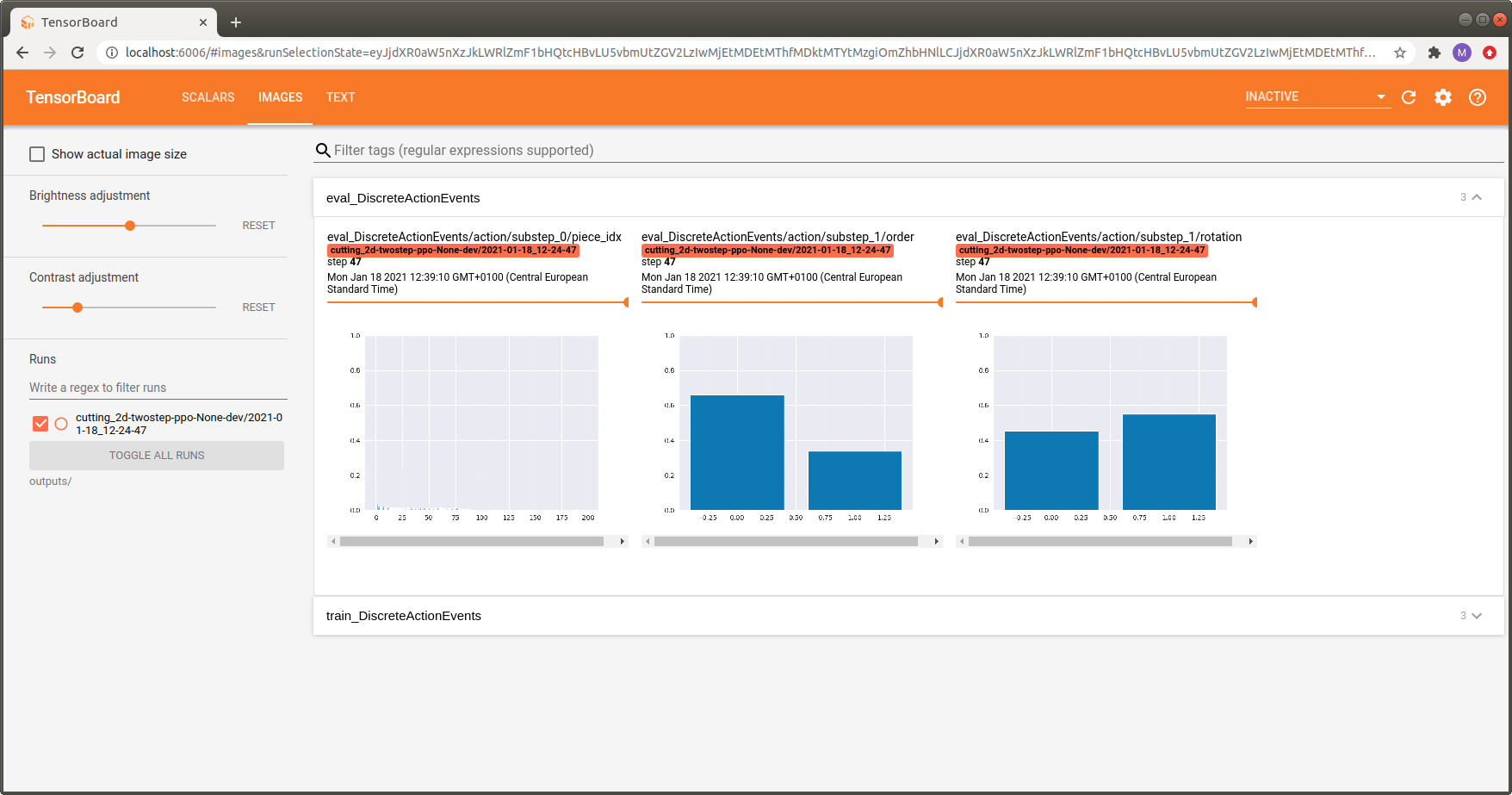
in the IMAGE tab.
(Useful for understanding the agent’s behaviour)
|
in the DISTRIBUTIONS and HISTOGRAMS tab.
(Useful for analysing observations)
|
|
|
Command Line Logging¶
Whenever you start a training run you will also get a command line output similar to the one shown below. Analogously to the Tensorboard log, Maze distinguishes between train and eval outputs and groups the items into semantically connected output blocks.
step|path | value
=====|============================================================================|====================
1|train MultiStepActorCritic..time_rollout ······················| 1.091
1|train MultiStepActorCritic..learning_rate ······················| 0.000
1|train MultiStepActorCritic..policy_loss 0 | -0.000
1|train MultiStepActorCritic..policy_grad_norm 0 | 0.001
1|train MultiStepActorCritic..policy_entropy 0 | 1.593
1|train MultiStepActorCritic..policy_loss 1 | -0.000
1|train MultiStepActorCritic..policy_grad_norm 1 | 0.008
1|train MultiStepActorCritic..policy_entropy 1 | 0.295
1|train MultiStepActorCritic..critic_value 0 | -0.199
1|train MultiStepActorCritic..critic_value_loss 0 | 116.708
1|train MultiStepActorCritic..critic_grad_norm 0 | 0.500
1|train MultiStepActorCritic..time_update ······················| 1.642
1|train DiscreteActionEvents action substep_0/piece_idx | [len:4000, μ:54.8]
1|train BaseEnvEvents reward median_step_count | 200.000
1|train BaseEnvEvents reward mean_step_count | 200.000
1|train BaseEnvEvents reward total_step_count | 4000.000
1|train BaseEnvEvents reward total_episode_count | 20.000
1|train BaseEnvEvents reward episode_count | 20.000
1|train BaseEnvEvents reward std | 1.465
1|train BaseEnvEvents reward mean | -71.950
1|train BaseEnvEvents reward min | -75.000
1|train BaseEnvEvents reward max | -70.000
1|train DiscreteActionEvents action substep_1/order | [len:4000, μ:0.5]
1|train DiscreteActionEvents action substep_1/rotation | [len:4000, μ:0.5]
1|train InventoryEvents piece_replenished mean_episode_total | 71.950
1|train InventoryEvents pieces_in_inventory step_max | 163.000
1|train InventoryEvents pieces_in_inventory step_mean | 69.946
1|train CuttingEvents valid_cut mean_episode_total | 200.000
1|train BaseEnvEvents kpi max/raw_piece_usage_..| 0.375
1|train BaseEnvEvents kpi min/raw_piece_usage_..| 0.350
1|train BaseEnvEvents kpi std/raw_piece_usage_..| 0.007
1|train BaseEnvEvents kpi mean/raw_piece_usage..| 0.360
Time required for epoch: 19.43s
Update epoch - 1
step|path | value
=====|============================================================================|====================
2|eval DiscreteActionEvents action substep_0/piece_idx | [len:800, μ:53.2]
2|eval BaseEnvEvents reward median_step_count | 200.000
2|eval BaseEnvEvents reward mean_step_count | 200.000
2|eval BaseEnvEvents reward total_step_count | 1600.000
2|eval BaseEnvEvents reward total_episode_count | 8.000
2|eval BaseEnvEvents reward episode_count | 4.000
2|eval BaseEnvEvents reward std | 1.414
2|eval BaseEnvEvents reward mean | -71.000
2|eval BaseEnvEvents reward min | -73.000
2|eval BaseEnvEvents reward max | -69.000
2|eval DiscreteActionEvents action substep_1/order | [len:800, μ:0.5]
2|eval DiscreteActionEvents action substep_1/rotation | [len:800, μ:0.5]
2|eval InventoryEvents piece_replenished mean_episode_total | 71.000
2|eval InventoryEvents pieces_in_inventory step_max | 145.000
2|eval InventoryEvents pieces_in_inventory step_mean | 68.031
2|eval CuttingEvents valid_cut mean_episode_total | 200.000
2|eval BaseEnvEvents kpi max/raw_piece_usage_..| 0.365
2|eval BaseEnvEvents kpi min/raw_piece_usage_..| 0.345
2|eval BaseEnvEvents kpi std/raw_piece_usage_..| 0.007
2|eval BaseEnvEvents kpi mean/raw_piece_usage..| 0.355
Where to Go Next¶
For further details please see the reference documentation.
For the bigger picture we refer to event and KPI logging as well as the Maze event system.
You might be also interested in observation distribution logging and action distribution logging.