Maze Environment Hierarchy¶
When working with an environment, it is desirable to maintain some modularity in order to be able to, for example, test different configurations of action and observation spaces, modify or record rollouts, or turn an existing flat environment into a structured one.
This page explains how Maze achieves such modularity by breaking down the Maze environment into smaller components and utilizing wrappers. It also provides a high-level overview of what you need to do to use a new or existing custom environment with Maze. (You can find guidance on that at the end of each section.)
For more references on the individual components or on how to write a new environment from scratch, see the Where to Go Next section at the end.
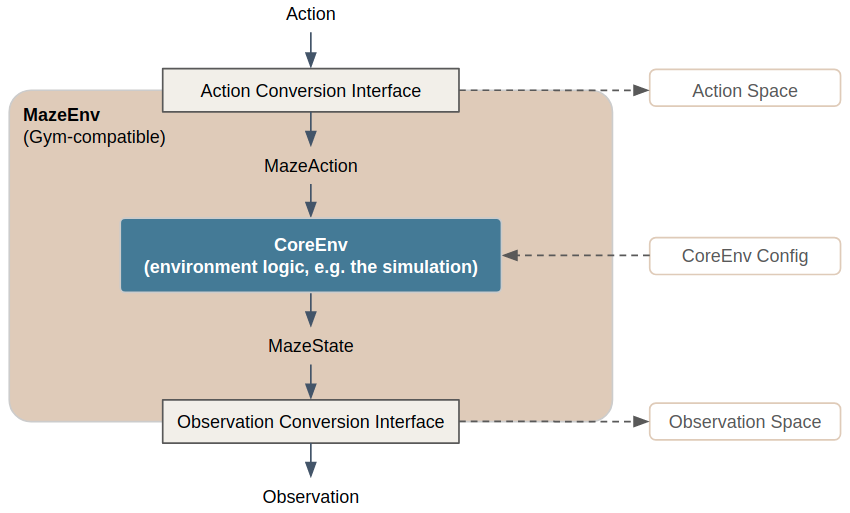
The following sections describe the main components:
Core environment, which implements the main environment mechanics, and works with MazeState and MazeAction objects.
Observation- and ActionConversionInterfaces which turn MazeState and MazeAction objects (custom to the core environment) into actions and observations (instances of Gym-compatible spaces which can be fed into a model).
Maze env, which encapsulates the core environment and implements functionality common to all environments above it (e.g. manages observation and action conversion).
Wrappers, which add a great degree of flexibility by allowing you to encapsulate the environment and observe or modify its behavior.
Structured environment interface, which Maze uses to model more complex scenarios such as multi-step (auto-regressive), multi-agent or hierarchical settings.
Here, we explain what parts a Maze environment is composed of and how to apply wrappers.
Core Environment¶
Core environment implements the main mechanics and functionality of the environment.
Its interface is compatible with the Gym environment interface with functions such as
step and reset.
The step function of the core environment takes an MazeAction
object and returns a MazeState object. There are no strict requirements on how these objects
should look – their structure is dependent on the needs of the core environment. However,
note that these objects should be serializable, so that they can be easily recorded
as part of trajectory data and inspected later.
Besides the Gym interface, core environment interface also contains a couple of hooks
that make it easy to support various features of maze, like recording trajectory of your
rollouts and then replaying these in a Jupyter notebook. These method include, e.g.,
get_renderer() and get_serializable_components(). You don’t have to use these
if you don’t need them (e.g. just return an empty dictionary to get_serializable_components()
if there are no additional components you would like to serialize with trajectory data) – but then,
some features of Maze might not be available.
If you want to use a new or existing environment with Maze, core environment is where you should start. Implement the core environment interface in your environment or encapsulate your environment in an core environment subclass.
Gym-Space Interfaces¶
Observation- and ActionConversionInterfaces translate MazeState and MazeAction objects (custom to the core environment) into actions and observations (instances of Gym-compatible spaces, i.e., usually a dictionary of numpy arrays which can be fed into a model) and vice versa.
It makes sense to extract this functionality in a separate objects, as format of actions and observations often needs to be swapped (to allow for different trained policies or heuristics). Treating space interfaces as separate objects encapsulates their configuration and separates it from the core environment functionality (which does not need to be changed when only, e.g., the format of the action space is being changed).
If you are creating a new Maze environment, you will need to implement at least one pair of interfaces – one for conversion of MazeStates into observations that your models can later consume, and other one for converting the actions produced by the model to the MazeActions your environment works with.
For more information on the space interfaces and how to customize your environment with them, refer to Customizing Core and Maze Environments.
Maze Environment¶
Maze environment encapsulates the core environment together with the space interfaces. Here, the functionality shared across all core environments is implemented – like management of the space interfaces, support for statistics and logging, and else.
Maze environment is the smallest unit that an RL agent can interact with, as it encapsulates the core functionality implemented by the core environment, space interfaces that translate the MazeState and MazeAction so that the model can understand it, and support for other optional features of Maze that you can add (like statistics logging).
If you are creating a new environment, you will likely not need to think of the Maze environment class much, as it is mostly concerned with functionalities shared across all Maze environments. You will still need to subclass it to have a distinct Maze environment class for your environment, but usually it is enough to override the initializer, there is no need to modify any of its other functionalities.
Wrappers¶
(This section provides an overview. See also Wrappers for more details.)
Wrappers are a very flexible way how to modify behavior of an environment. As the name implies, a wrapper encapsulates the whole environment in it. This means that the wrapper has complete control over the behavior of the environment and can modify it as suited.
Note also that another wrapper can also be applied to an already wrapped environment.
In this case, each method call (such as step) will traverse through the whole wrapper
stack, from the outer-most wrapper to the Maze env, with each wrapper being able to
intercept and modify the call.
Maze provides superclasses for commonly used wrapper types:
ObservationWrapper can manipulate the observation before it reaches the agent. Observation wrappers are used for example for observation normalization wrapper or masking. Usually, this is the most common type of wrapper used.
RewardWrapper can manipulate the reward before it reaches the model.
ActionWrapper can manipulate the action the model produced before it is converted using ActionConversionInterface in Maze environment.
Wrapper is the common superclass of all the wrappers listed above. It can be subclassed directly if you need to provide some more elaborate functionality, like turning your flat environment into a structured multi-step one
If you are creating a new Maze environment, wrappers are optional. Unless you have some very special needs, the wide variety of wrappers provided by Maze (like observation normalization wrapper or trajectory recording wrapper) should work with any Maze environment out of the box. However, you might need to implement a custom wrapper if you want to modify the behavior of your environment in some more customized manner, like turning your flat environment into a structured multi-step one.
For more information on wrappers and customization, see Wrappers.
Structured Environments¶
This section provides an high-level overview of structured environments. See Control Flows with Structured Environments for more details and examples.
Maze uses the StructuredEnv
concept to model more complex settings, such as multi-step (auto-regressive),
multi-agent or hierarchical settings.
While such settings can indeed be quite complex,
the StructuredEnv interface itself
is rather simple under the hood. In summary, during each step in the environment:
The agent needs to ask which policy should act next. The environment exposes this using the
actor_idmethod.The agent then should evaluate the observation using the policy corresponding to the current actor ID, and issue the desired action using the
stepfunction in a usual Gym-like manner.
Note that the Actor ID, which identifies the currently active policy, is composed of (1) the sub-step key and (2) the index of the current actor in scope of this sub-step (as in some settings, there might be multiple actors per sub-step key).
Maze uses the StructuredEnv
interface in all settings by default, and other Maze components like
TorchPolicy
support it (and make it convenient to work with) out of the box.
Where to Go Next¶
After understanding how Maze environment hierarchy works, you might want to:
See how Hydra configuration works and how environments can be customized through it
See more about how to customize an existing environment with wrappers
Get more information on how to write a new Maze environment from scratch
See how Maze environments dispatch events to facilitate statistics collection and other forms of logging
Understand how policies and agents are structured
Also, note that the classes described above (like Core environment and Maze environment) themselves implement a set of interfaces that facilitate some of Maze functions, like EventEnvMixin interfacing the Event system or RenderEnvMixin facilitating rendering. You will likely not need to work with these directly, and hence they are not described here in detail. However, if you need to know more about these, head to the reference documentation.