Training¶
Here we show how to train a policy on a standard Gym or custom environment using algorithms and models from Maze. This guide focuses on the main mechanics of Maze training runs, plus also gives some pointers on how to customize the training with custom environments (using the tutorial Maze 2D-cutting environment as an example), models, etc.
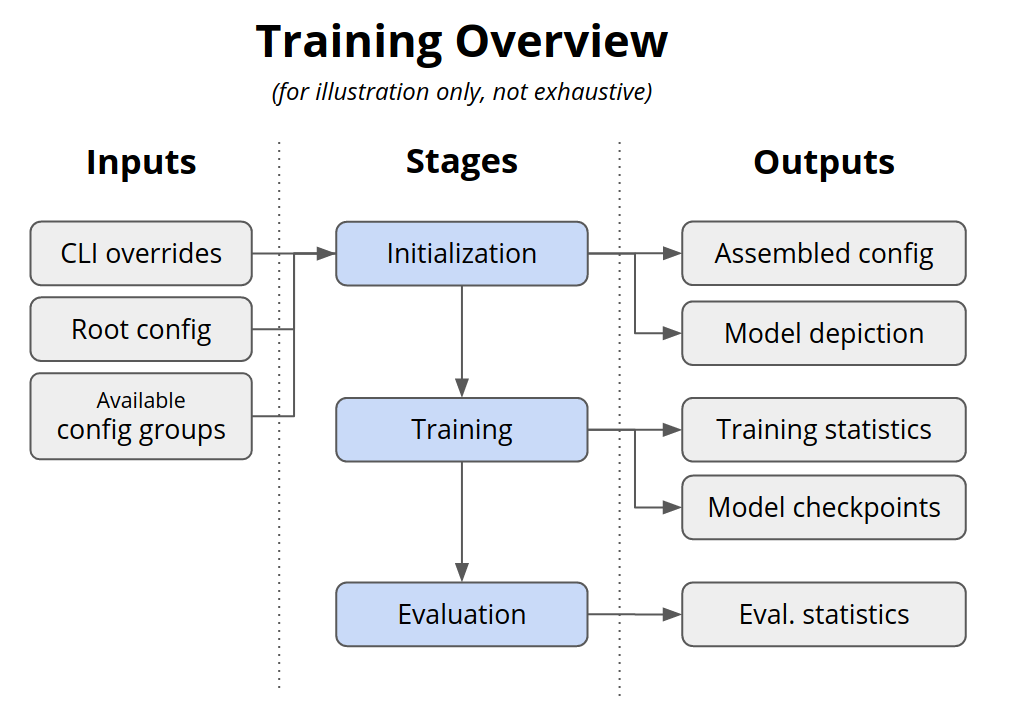
The figure below shows a conceptual overview of the Maze training workflow.
On this page:
The first example demonstrates training with the default settings. The main purpose is to show how the Maze training pipeline works in general.
The second example explains how you can customize training on standard Gym and Maze environments (for which configuration files are already provided by Maze).
The third example explains how you can resume previous training runs.
The following section then explains what you need to customize training for your own project, including custom components and configuration files.
Finally, the last section shows how to launch training directly from Python (avoiding the CLI).
In order to fully understand the configuration mechanisms used here, you should familiarize yourself with how Maze makes use of the Hydra configuration framework.
Example 1: Your First Training Run¶
We can train a policy from scratch on the Cartpole environment with default settings using the command:
maze-run -cn conf_train env=gym_env env.name=CartPole-v1
The -cn conf_train argument specifies that we would like to use
conf_train.yaml as our root config file. This is
needed as by default, configuration for rollouts is used.
Furthermore, we specify that gym_env configuration should be used, with
CartPole-v1 as the Gym environment name. (For more information on how to read and customize the default configuration files,
see Hydra overview.)
Such a training run consists of these main stages, loaded based on the default configuration provided by Maze:
The full configuration is assembled via Hydra based on the config files available, the defaults set in root config, and the overrides you provide via CLI (see Hydra overview to understand more about this process).
Hydra creates the output directory where all output files will be stored.
The full configuration of the job is logged: (1) to standard output, (2) as a text entry to your Tensorboard logs, and (3) as a YAML file in the output directory.
If the observation normalization wrapper is present, observation normalization statistics are collected and stored (note that no wrappers are applied by default).
Policies and critics are initialized and their graphical depictions saved.
The training starts, statistics are displayed in console and stored to a Tensorboard file, and current best model versions are saved (by default to
state_dict.ptfile).Once the training is done, final evaluation runs are performed and final model versions saved. (When the training is done depends on the training runner. Usually, this is specified using the
runner.n_epochsargument, but the training can also end with early stopping if there is no more improvement).
As the job is running, you should see the statistics from the training and evaluation runs printed in your console, as mentioned in the 6. step:
...
********** Iteration 3 **********
step|path | value
=====|========================================================================================|====================
4|eval DiscreteActionEvents action substep_0/action | [len:281, μ:0.5]
4|eval BaseEnvEvents reward median_step_count | 18.500
4|eval BaseEnvEvents reward mean_step_count | 28.100
4|eval BaseEnvEvents reward total_step_count | 928.000
4|eval BaseEnvEvents reward total_episode_count | 40.000
4|eval BaseEnvEvents reward episode_count | 10.000
4|eval BaseEnvEvents reward std | 16.447
4|eval BaseEnvEvents reward mean | 28.100
4|eval BaseEnvEvents reward min | 16.000
4|eval BaseEnvEvents reward max | 66.000
-> new overall best model 28.10000!
...
This main structure remains similar for all environment and training configurations.
Example 2: Customizing with Provided Components¶
When your Maze job is launched using maze-run from the CLI, the following happens under
the hood:
A job configuration is assembled by putting available configuration files together with the overrides you specify as arguments to the run command. More on that can be found in configuration documentation page, specifically in Hydra overview.
The complete assembled configuration is handed over to the Maze runner specified in the configuration (in the
runnergroup). This runner then launches and manages the training (or any other) job.
The common points for customizing the training run correspond to the configuration groups listed in the training root config file, namely:
Environment (
envconfiguration group), configuring which environment the training runs on, as well as customizing any other inner configuration of the environment, if available (like raw piece size in 2D cutting environment)Training algorithm (
algorithmconfiguration group), specifying the algorithm used and configuration for itModel (
modelconfiguration group), specifying how the models for policies and (optionally) critics should be assembledRunner (
runnerconfiguration group), specifying options for how the training is run (e.g. locally, in development mode, or using Ray on a Kubernetes cluster). The runner is also the main object responsible for administering the whole training run (and runners are thus specific to individual algorithms used).
Maze provides a host of configuration files useful for working with standard Gym environments and environments provided by Maze (such as the 2D cutting environment). Hence, to use these, it suffices to supply appropriate overrides, without writing any additional configuration files.
By default, the gym_env configuration is used, which allows us to specify the Gym env
that we would like to instantiate:
maze-run -cn conf_train env=gym_env env.name=LunarLander-v3
With appropriate overrides, we can also include vector observation model and wrappers (providing normalization):
maze-run -cn conf_train env=gym_env env.name=LunarLander-v3 wrappers=vector_obs model=vector_obs
Alternatively, we could use the tutorial Cutting 2D environment:
maze-run -cn conf_train env=tutorial_cutting_2d_struct_masked wrappers=tutorial_cutting_2d model=tutorial_cutting_2d_struct_masked
Further, by default, the algorithm used is Evolution Strategies (the implementation is provided by Maze). To use a different algorithm, e.g. PPO with a shared critic, we just need to add the appropriate overrides:
maze-run -cn conf_train algorithm=ppo env=tutorial_cutting_2d_struct_masked wrappers=tutorial_cutting_2d model=tutorial_cutting_2d_struct_masked
To see all the configuration files available out-of-the-box, check out the maze/conf package.
Example 3: Resuming Previous Training Runs¶
In case a training run fails (e.g. because your server goes down) there is no need to restart training
entirely from scratch. You can simply pass a previous experiment as an input_dir and the Maze trainers will
initialize the model weights including all other relevant artifacts such as normalization statistics from the provided
directory. Below you find a few examples where this might be useful.
This is the initial training run:
maze-run -cn conf_train env=gym_env env.name=LunarLander-v3 algorithm=ppo
We could also resume training with a refined learning rate:
maze-run -cn conf_train env=gym_env env.name=LunarLander-v3 algorithm=ppo algorithm.lr=0.0001 input_dir=outputs/<experiment-dir>
or even with a different (compatible) trainer such as a2c:
Training in Your Custom Project¶
While the default environments and configurations are nice to get started quickly or test different approaches in standard scenarios, the primary focus of Maze are fully custom environments and models solving real-world problems (which are of course much more fun as well!).
The best place to start with a custom environment is the Maze step by step tutorial (mentioned already in the previous section) showing how to implement a custom Maze environment from scratch, along with respective configuration files (see also Hydra: Your Own Configuration Files).
Then, you can easily launch your environment by supplying your own configuration file (here we use one from the tutorial):
maze-run -cn conf_train env=tutorial_cutting_2d_struct_masked wrappers=tutorial_cutting_2d model=tutorial_cutting_2d_struct_masked
For links to more customization options (like building custom models with Maze Perception Module), check out the Where to Go Next section.
While customizing other configuration groups listed in the previous section
(e.g., algorithm, runner) is not needed as often, all of these can be customized
in an analogous way (i.e., implement your own components that plug into the framework
instead of the default ones, and then add your own config
to be able to configure them from the command line).
Plain Python Training¶
Maze offers training also from within your Python script. In most use cases, it will probably be more convenient to launch training directly from the CLI and just implement your custom components (wrappers, environments, models, etc.) as needed. However, the inner architecture of Maze should be sufficiently modular to allow you to modify just the parts that you want.
Because each of the algorithms included in Maze has slightly different needs, the usage will
likely slightly differ. However, regardless of which algorithm you intend to use,
the TrainingRunner
subclasses offer good examples of what components you will need for launching
training directly from Python.
Specifically, you’ll need to concentrate on the run method, which takes as an argument the full
assembled hydra configuration (which is printed to the command line every time you launch a job).
Usually, the run method does roughly the following:
Instantiates the environment and policy components (some of this functionality is provided by the shared
TrainingRunnersuperclass, as a large part of that is common for all training runners)Assembles the policy and critics into a structured policy
Instantiates the trainer and any other components needed for training
Launches the training
TrainingRunner initializes the runner and TrainingRunner runs the training.
For example, these are the setup and run methods taken directly from the evolution strategies runner:
@override(TrainingRunner)
def setup(self, cfg: DictConfig) -> None:
"""
Setup the training master node.
"""
super().setup(cfg)
# --- init the shared noise table ---
print("********** Init Shared Noise Table **********")
self.shared_noise = SharedNoiseTable(count=self.shared_noise_table_size)
# --- initialize policies ---
torch_policy = TorchPolicy(networks=self._model_composer.policy.networks,
distribution_mapper=self._model_composer.distribution_mapper, device="cpu")
torch_policy.seed(self.maze_seeding.global_seed)
# support policy wrapping
if self._cfg.algorithm.policy_wrapper:
policy = Factory(Policy).instantiate(
self._cfg.algorithm.policy_wrapper, torch_policy=torch_policy)
assert isinstance(policy, Policy) and isinstance(policy, TorchModel)
torch_policy = policy
print("********** Trainer Setup **********")
self._trainer = ESTrainer(
algorithm_config=cfg.algorithm,
torch_policy=torch_policy,
shared_noise=self.shared_noise,
normalization_stats=self._normalization_statistics
)
# initialize model from input_dir
self._init_trainer_from_input_dir(trainer=self._trainer, state_dict_dump_file=self.state_dict_dump_file,
input_dir=cfg.input_dir)
self._model_selection = BestModelSelection(dump_file=self.state_dict_dump_file, model=torch_policy,
dump_interval=self.dump_interval)
@override(TrainingRunner)
def run(
self,
n_epochs: Optional[int] = None,
distributed_rollouts: Optional[ESDistributedRollouts] = None,
model_selection: Optional[ModelSelectionBase] = None
) -> None:
"""
See :py:meth:`~maze.train.trainers.common.training_runner.TrainingRunner.run`.
:param distributed_rollouts: The distribution interface for experience collection.
:param n_epochs: Number of epochs to train.
:param model_selection: Optional model selection class, receives model evaluation results.
"""
print("********** Run Trainer **********")
env = self.env_factory()
env.seed(self.maze_seeding.generate_env_instance_seed())
# run with pseudo-distribution, without worker processes
self._trainer.train(
n_epochs=self._cfg.algorithm.n_epochs if n_epochs is None else n_epochs,
distributed_rollouts=self.create_distributed_rollouts(
env=env, shared_noise=self.shared_noise,
agent_instance_seed=self.maze_seeding.generate_agent_instance_seed()
) if distributed_rollouts is None else distributed_rollouts,
model_selection=self._model_selection if model_selection is None else model_selection
)
Where to Go Next¶
After training, you might want to roll out the trained policy to further evaluate it or record the actions taken.
To create a custom Maze environment, you might want to review Maze environment hierarchy and creating a Maze environment from scratch.
To build custom Maze models, have a look at the Maze Perception Module.
To better understand how to configure custom environments and other components of your project, you might want to review the more advanced parts of configuration with Hydra.