Hierarchical RL¶
Note
Reinforcement learning is prone to scaling and generalization issues. With large action spaces, it takes a lot of time and resources for agents to learn the desired behaviour successfully. Hierarchical reinforcement learning (HRL) attempts to resolve this by decomposing tasks into a hierarchy of subtasks. This addresses the curse of dimensionality by mitigating or avoiding the exponential growth of the action space.
Beyond reducing the size of the action space HRL also provides an opportunity for easier generalization. Through its modularization of tasks, learned policies for super-tasks may be reused even if the underlying sub-tasks change. This enables transfer learning between different problems in the same domain.
Note that the action space can also be reduced with action masking as used in e.g. StarCraft II: A New Challenge for Reinforcement Learning, which indicates the invalidity of certain actions in the observations provided to the agent. HRL and action masking can be used in combination. The latter doesn’t address the issue of generalization and transferability though. Whenever possible and sensible we recommend to use both.
Motivating Example¶
Consider a pick and place robot. It is supposed to move to an object, pick it up, move it to a different location and place it there. It consists of different segments connected via joints that enable free movement in three dimensions and a gripper able to grasp and hold the target object. The gripper may resemble a pair of tongs or be more complex, e.g. be built to resemble a human hand.
A naive approach would present all possible actions, i.e. rotating the arm segments and moving the gripper, in a single action space. If the robot’s arm segments can move in \(n\) and its gripper in \(m\) different ways, a flat action space would consist of \(n * m\) different actions.
The task at hand can be intuitively represented as a hierarchy however: The top-level task is composed of the task sequence of “move”, “grasp”, “move”, “place”. This corresponds to a top-level policy choosing one of three sub-policies enacting primitive actions, i.e. arm or gripper movements. This enables the reusability of individual (sub-)policies for other tasks in the same domain.
Control Flow¶
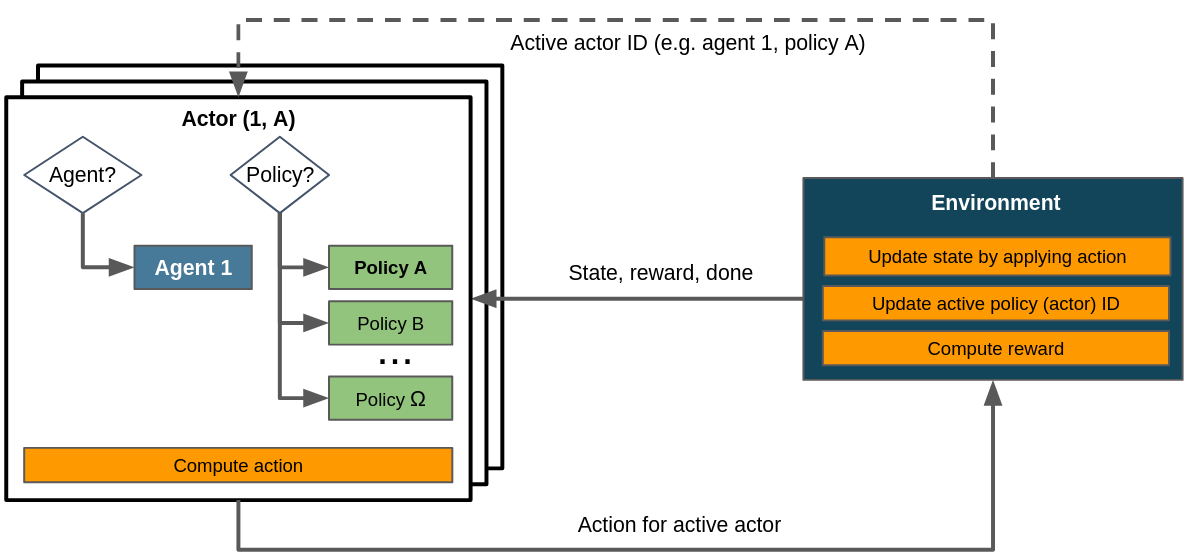
Control flow within a HRL scenario assuming a single agent. The task hierarchy is built implicitly in step(). Dashed lines denote the exchange of information on demand as opposed to doing so passing it to or returning it from step().¶
The control flow for HRL scenarios doesn’t obviously reflect the hierarchical aspect. This is because the definition and execution of the task hierarchy happens implicitly in step(): the environment determines which task is currently active and which task should be active at the end of the current step. This allows for an arbitrarily flexible and complex task dependency graph. The possibility to implement a different ObservationConversionInterface and ActionConversionInterface for each policy enables to tailor actions and observations to the respective task.
This control flow bears strong similarity to the one for multi-stepping<struct_env_multistep> - in fact, multi-stepping could be seen as a special kind of hierarchical RL with a fixed task sequence and a single level of hierarchy.