5. Training the MazeEnv¶
The complete code for this part of the tutorial can be found here
# file structure
- cutting_2d
- main.py
- env ...
- space_interfaces ...
- conf
- env
- tutorial_cutting_2d_basic.yaml # new
- model
- tutorial_cutting_2d_basic.yaml # new
- wrappers
- tutorial_cutting_2d_basic.yaml # new
Note
Hydra only accepts .yaml as file extension.
5.1. Hydra Configuration¶
The entire Maze workflow is boosted by the Hydra configuration system. To be able to perform our first training run via the Maze CLI we have to add a few more config files. Going into the very details of the config structure is for now beyond the scope of this tutorial. However, we still provide some information on the parts relevant for this example.
The config file for the maze_env_factory looks as follows:
# @package env
_target_: tutorial_maze_env.part03_maze_env.env.maze_env.maze_env_factory
# parametrizes the core environment
max_pieces_in_inventory: 200
raw_piece_size: [100, 100]
static_demand: [30, 15]
Additionally, we also provide a wrapper config but refer to Customizing Environments with Wrappers for details.
# @package wrappers
# limits the maximum number of time steps of an episode
maze.core.wrappers.time_limit_wrapper.TimeLimitWrapper:
max_episode_steps: 200
# flattens the dictionary observations to work with DenseLayers
maze.core.wrappers.observation_preprocessing.preprocessing_wrapper.PreProcessingWrapper:
pre_processor_mapping:
- observation: inventory
_target_: maze.preprocessors.FlattenPreProcessor
keep_original: false
config:
num_flatten_dims: 2
# monitoring wrapper
maze.core.wrappers.monitoring_wrapper.MazeEnvMonitoringWrapper:
observation_logging: false
action_logging: true
reward_logging: false
To learn more about the model config in conf/env_model/tutorial_cutting_2d_basic.yaml
you can visit the introduction on how to work with template models.
5.2. Training an Agent¶
Once the config is set up we are good to go to start our first training run (in the cmd below with the PPO algorithm) via the CLI with
maze-run -cn conf_train env=tutorial_cutting_2d_basic wrappers=tutorial_cutting_2d_basic \
model=tutorial_cutting_2d_basic algorithm=ppo
Running the trainer should print a command line output similar to the one shown below.
step|path | value
=====|============================================================================|====================
12|train MultiStepActorCritic..time_epoch ······················| 24.333
12|train MultiStepActorCritic..time_rollout ······················| 0.754
12|train MultiStepActorCritic..learning_rate ······················| 0.000
12|train MultiStepActorCritic..policy_loss 0 | -0.016
12|train MultiStepActorCritic..policy_grad_norm 0 | 0.015
12|train MultiStepActorCritic..policy_entropy 0 | 0.686
12|train MultiStepActorCritic..critic_value 0 | -56.659
12|train MultiStepActorCritic..critic_value_loss 0 | 33.026
12|train MultiStepActorCritic..critic_grad_norm 0 | 0.500
12|train MultiStepActorCritic..time_update ······················| 1.205
12|train DiscreteActionEvents action substep_0/order | [len:8000, μ:0.5]
12|train DiscreteActionEvents action substep_0/piece_idx | [len:8000, μ:169.2]
12|train DiscreteActionEvents action substep_0/rotation | [len:8000, μ:1.0]
12|train BaseEnvEvents reward median_step_count | 200.000
12|train BaseEnvEvents reward mean_step_count | 200.000
12|train BaseEnvEvents reward total_step_count | 96000.000
12|train BaseEnvEvents reward total_episode_count | 480.000
12|train BaseEnvEvents reward episode_count | 40.000
12|train BaseEnvEvents reward std | 34.248
12|train BaseEnvEvents reward mean | -186.450
12|train BaseEnvEvents reward min | -259.000
12|train BaseEnvEvents reward max | -130.000
To get a nicer view on these numbers we can also take a look at the stats with Tensorboard.
tensorboard --logdir outputs
You can view it with your browser at http://localhost:6006/.
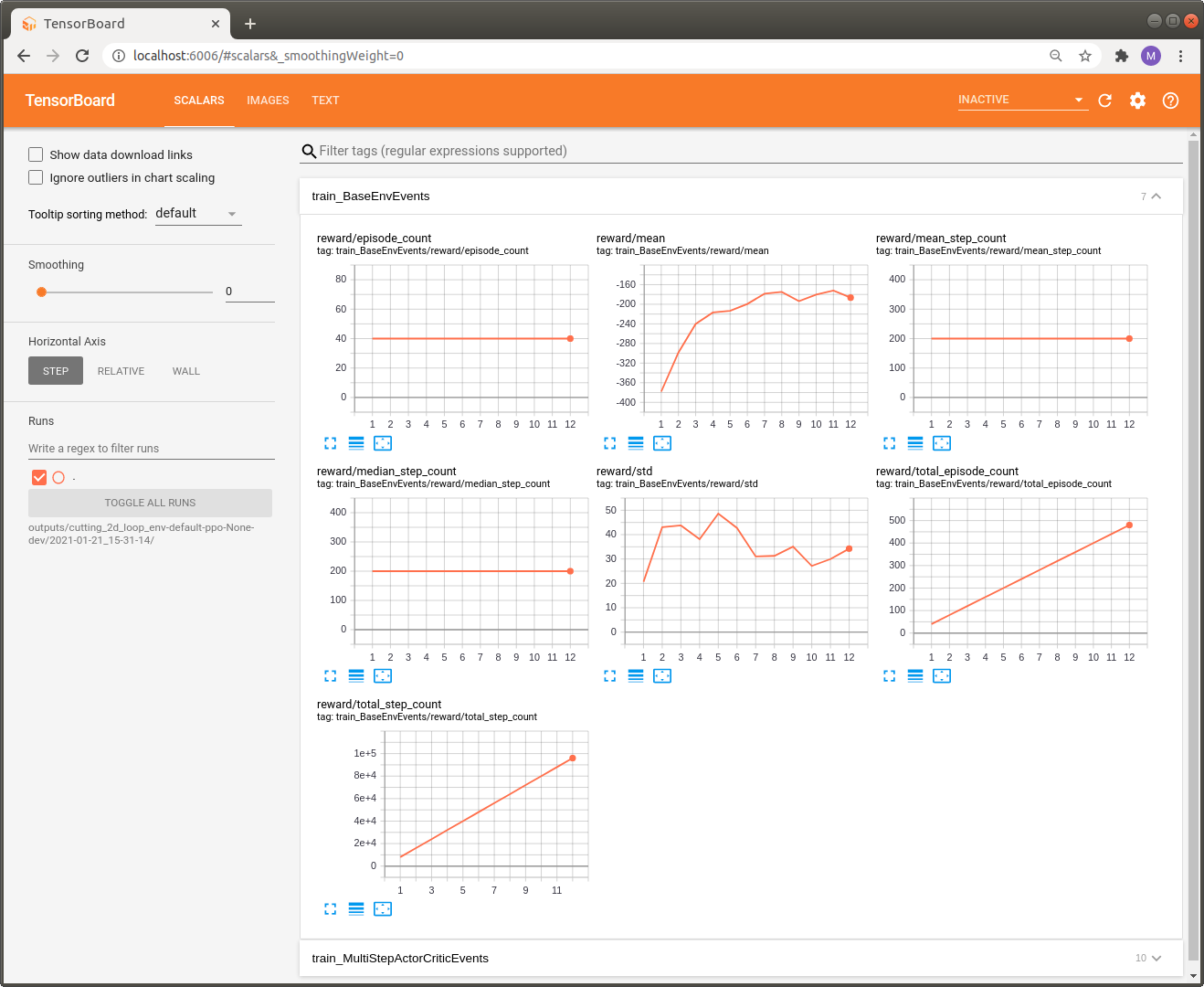
For now we can only inspect standard metrics such as reward statistics or mean_step_counts per episode. Unfortunately, this is not too informative with respect to the cutting problem we are currently addressing. In the next part we will show how to make logging much more informative by introducing events and KPIs.