Hydra: Overview¶
The motivation behind using Hydra is primarily to:
Keep separate components (e.g., environment, policy) in individual YAML files which are easier to understand
Run multiple experiments with different components (like using two different environment configurations, or training with PPO vs. A2C) without duplicating the whole config file
Make components/values different from the defaults immediately visible (with, e.g.,
maze-run runner=sequential)
Below, the core concepts of Hydra as Maze uses it are described:
Introduction explains the core concepts of assembling configuration with Hydra
Config Root & Defaults explains how the root config file works and how default components are specified
Overrides show how you can easily customize the config parameters without duplicating the config file, and have Hydra assemble the config and log it for you
Output Directory shows how Hydra creates separate directories for your runs automatically. It is a bit separated from the previous concepts but still important for running your jobs.
Runner concept section explains how the Hydra config is handled by Maze to launch various kinds of jobs (like rollout or train runs) with different configurations
Introduction¶
Hydra is a configuration framework that, in short, allows you to:
Break down your configuration into multiple smaller YAML files (representing individual components)
Launch your job through CLI providing overrides for individual components or values and have Hydra assemble the config for you
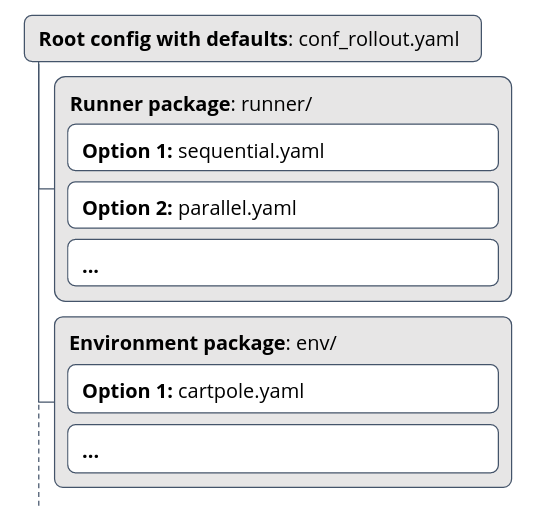
Ad (1): For illustrative purposes, this is an example of how your Hydra config structure can look like:
Ad (2): With the structure above, you could then launch your jobs with specified components (again, this is only for illustrative purposes):
maze-run runner=parallel
Or, you can even override any individual value anywhere in the config like this:
maze-run runner=parallel runner.n_processes=10
You can also review the basic example and composition example at Hydra docs.
Configuration Root, Groups and Defaults¶
The starting place for a Hydra config is the root configuration file. It lists (1) the individual
configuration groups that you would like to use along with their defaults, and (2) any other
configuration that is universal. A simple root config file might look like this (all of these examples
are snippets taken from maze config, shortened for brevity):
# These are the individual config components with their defaults
defaults:
- runner: parallel
- env: cartpole
- wrappers: default
optional: true
# ...
# Other values that are universally applicable (still can be changed with overrides)
log_base_dir: outputs
# ...
The snippet runner: parallel tells Hydra to look for a file runner/parallel.yaml and
transplant its contents under the runner: key. (If optional: true is specified,
Hydra does not raise an error when such a config file cannot be found.)
Hence, if the runner/parallel.yaml file looks like this:
n_processes: 5
n_episodes: 50
# ...
the final assembled config would look like this:
runner:
n_processes: 5
n_episodes: 50
# ...
env:
# ...
Overrides¶
When running your job through a command line, you can customize individual bits of your configuration via command-line arguments.
As briefly demonstrated above, you can override individual defaults in the config file.
For example, when running a Maze rollout, the default runner is parallel, but
you could specify the sequential runner instead:
$ maze-run runner=sequential
Besides overriding specifying the config components, you can also override individual values in the config:
$ maze-run runner=sequential runner.max_episode_steps=1000
There is also more advanced syntax for adding/removing config keys and other patterns – for this, you can consult Hydra docs regarding basic overrides and extended override syntax.
Output Directory¶
Hydra also by default handles the output directory for each job you run.
By default, outputs is used as the base output directory and a new subdirectory
is create inside for each run. Here, Hydra also logs the configuration for the current
job in the .hydra subdirectory, so that you can always get back to it.
You can override the hydra output directory as follows:
$ maze-run hydra.run.dir=my_dir
More on the output directory setting can be found in Hydra docs: Output/Working directory and customizing working directory pattern.
Maze Runner Concept¶
In Maze, the maze-run command (that you have seen above already) is the single central
utility for launching all sorts of jobs, like training or rollouts.
Under the hood, when you launch such a job, the following happens:
Maze checks the
runnerpart of the Hydra configuration that was passed through the command. And instantiates a runner object from it (subclass ofRunner).(The
runnercomponent of the configuration always specifies the Runner class to be instantiated, along with any other arguments it needs at initialization.)Maze then calls the
runmethod on the instantiated runner and passes it the whole config, as obtained from Hydra.
This enables the maze-run command to keep a lot of variability without much coupling
of the individual functionalities. For example, rollouts are run through subclasses
of RolloutRunner
and trainings through subclasses of
TrainingRunner.
You are also free to create your own subclasses for rollouts, trainings or any completely different use cases.
Where to Go Next¶
After understanding the basics of how Maze uses Hydra, you might want to:
Try running a rollout using Hydra configuration through command line to put these ideas into action
Create custom Hydra configuration files for your project
Understand the advanced concepts of Hydra