A First Example¶
This example shows how to train and rollout a policy for the CartPole environment with A2C. It also gives a small glimpse into the Maze framework.
Training and Rollouts¶
To train a policy with the synchronous advantage actor-critic (A2C), run:
$ maze-run -cn conf_train env.name=CartPole-v0 algorithm=a2c algorithm.n_epochs=5
rc = RunContext(algorithm="a2c", overrides={"env.name": "CartPole-v0"})
rc.train(n_epochs=5)
All training outputs including model weights will be stored in
outputs/<exp-dir>/<time-stamp>
(for example outputs/gym_env-flatten_concat-a2c-None-local/2021-02-23_23-09-25/).
To perform rollouts for evaluating the trained policy, run:
$ maze-run env.name=CartPole-v0 policy=torch_policy input_dir=outputs/<exp-dir>/<time-stamp>
env = GymMazeEnv(env=cartpole_env)
obs = env.reset()
for i in range(10):
action = rc.compute_action(obs)
obs, rewards, dones, info = env.step(action)
This performs 50 rollouts and prints the resulting performance statistics to the command line:
step|path | value
=====|==================================================================|==================
1|rollout_stats DiscreteActionEvents action substep_0/action | [len:7900, μ:0.5]
1|rollout_stats BaseEnvEvents reward median_step_count | 157.500
1|rollout_stats BaseEnvEvents reward mean_step_count | 158.000
1|rollout_stats BaseEnvEvents reward total_step_count | 7900.000
1|rollout_stats BaseEnvEvents reward total_episode_count | 50.000
1|rollout_stats BaseEnvEvents reward episode_count | 50.000
1|rollout_stats BaseEnvEvents reward std | 31.843
1|rollout_stats BaseEnvEvents reward mean | 158.000
1|rollout_stats BaseEnvEvents reward min | 83.000
1|rollout_stats BaseEnvEvents reward max | 200.000
To see the policy directly in action you can also perform sequential rollouts with rendering:
$ maze-run env.name=CartPole-v0 policy=torch_policy input_dir=outputs/<exp-dir>/<time-stamp> \
runner=sequential runner.render=true
Note
Managed rollouts are not yet fully supported by our Python API, but will follow soon.

Tensorboard¶
To watch the training progress with Tensorboard start it by running:
tensorboard --logdir outputs/
and view it with your browser at http://localhost:6006/.
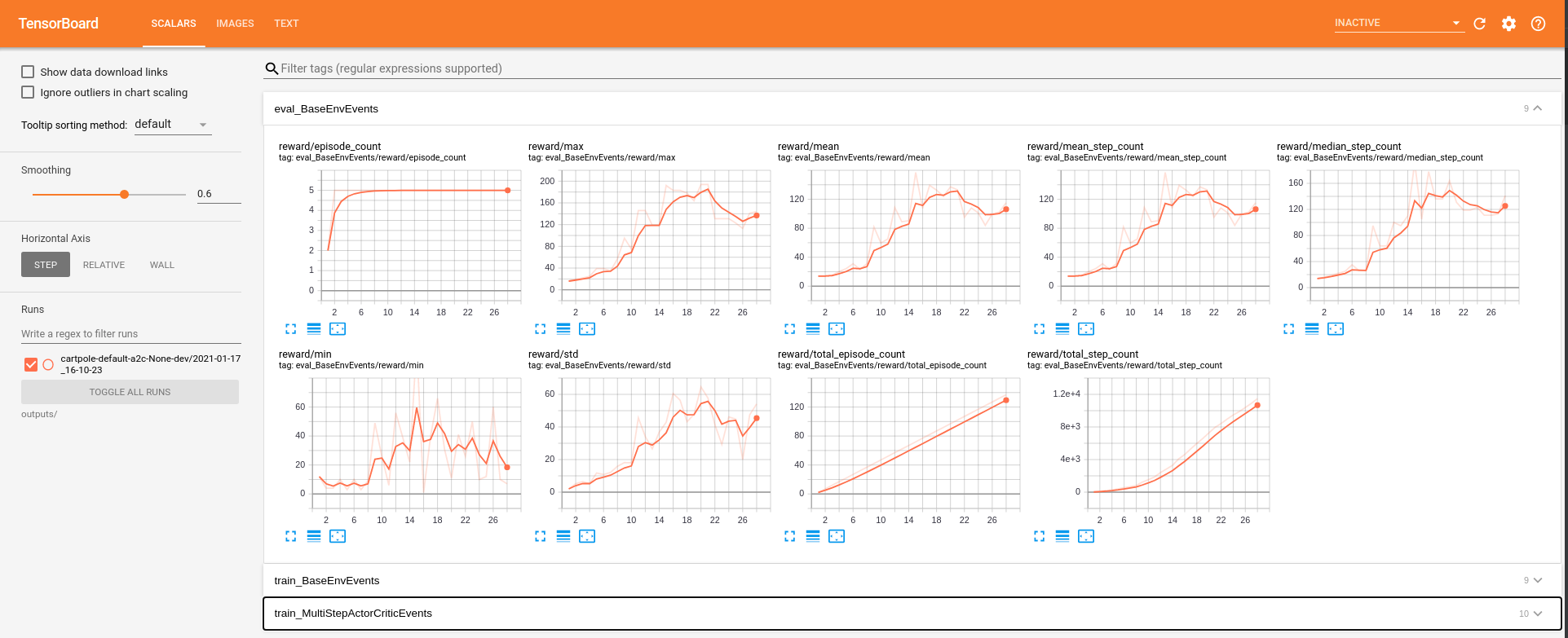
Training Outputs¶
For easier reproducibility Maze writes the full configuration compiled with Hydra to the command line an preserves it in the TEXT tab of Tensorboard along with the original training command.
algorithm:
critic_burn_in_epochs: 0
deterministic_eval: false
device: cpu
entropy_coef: 0.00025
epoch_length: 25
eval_repeats: 2
gae_lambda: 1.0
gamma: 0.98
lr: 0.0005
max_grad_norm: 0.0
n_epochs: 5
n_rollout_steps: 100
patience: 15
policy_loss_coef: 1.0
value_loss_coef: 0.5
env:
_target_: maze.core.wrappers.maze_gym_env_wrapper.make_gym_maze_env
name: CartPole-v0
input_dir: ''
log_base_dir: outputs
model:
...
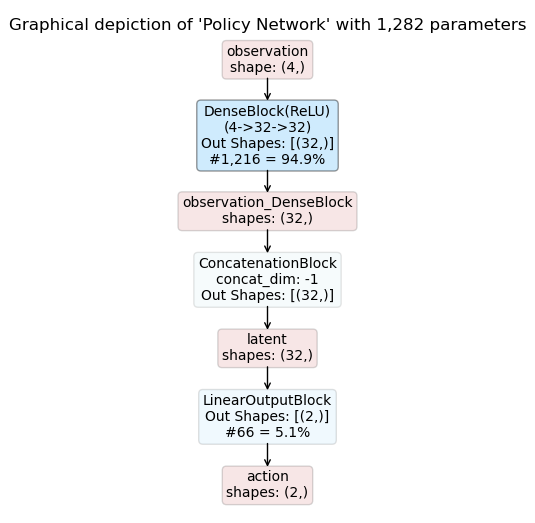
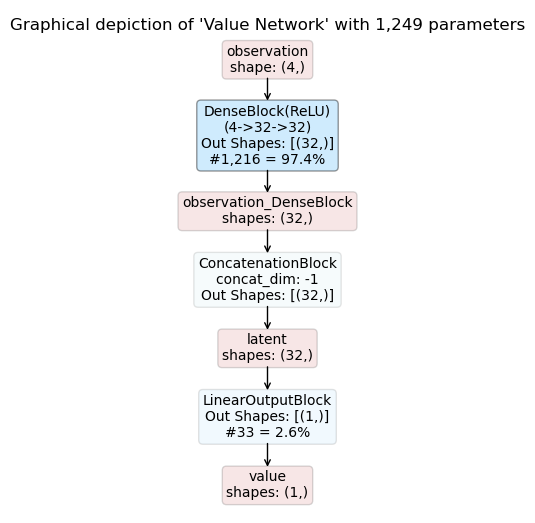
You will also find PDFs showing the inference graphs of the policy and critic networks in the experiment output directory. This turns out to be extremely useful when playing around with model architectures or when returning to experiments at a later stage.