Multi-Stepping¶
Note
- Recommended reads prior to this article:
We define multi-stepping as the execution of more than one action (or sub-step) in a single step. This is motivated by problem settings in which a certain sequence of actions is known a priori. In such cases incorporating this knowledge can significantly increase learning efficiency. The stock cutting problem poses an example: It is known, independently from the specifics of the environment’s state, that fulfilling a single customer order for a piece involves (a) picking a piece at least as big as the ordered item (b) cutting it to the correct size.
While it is not trivial to decide which items to pick for which orders and how to cut them, the sequence of piece selection before cutting is constant - there is no advantage to letting our agent figure it out by itself. Maze permits to incorporate this sort of domain knowledge by enabling to select and execute more than one action in a single step. This is done by utilizing the actor mechanism to execute multiple policies in a fixed sequence.
In the case of the stock cutting problem two policies could be considered: “select” and “cut”. The piece selection action might be provided to the environment at the beginning of each step, after which the cutting policy - conditioned on the current state with the already selected piece - can be queried to produce an appropriate cutting action.
An implementation of a multi-stepping environment for the stock cutting problem can be found here.
Control Flow¶
In general, the control flow for multi-stepping environments involve at least two policies and one agent. It is easily possible, but not necessary, to include multiple agents in a multi-step scenario. The following image depicts a multi-step setup with one agent and an arbitrary number of sub-steps/policies.
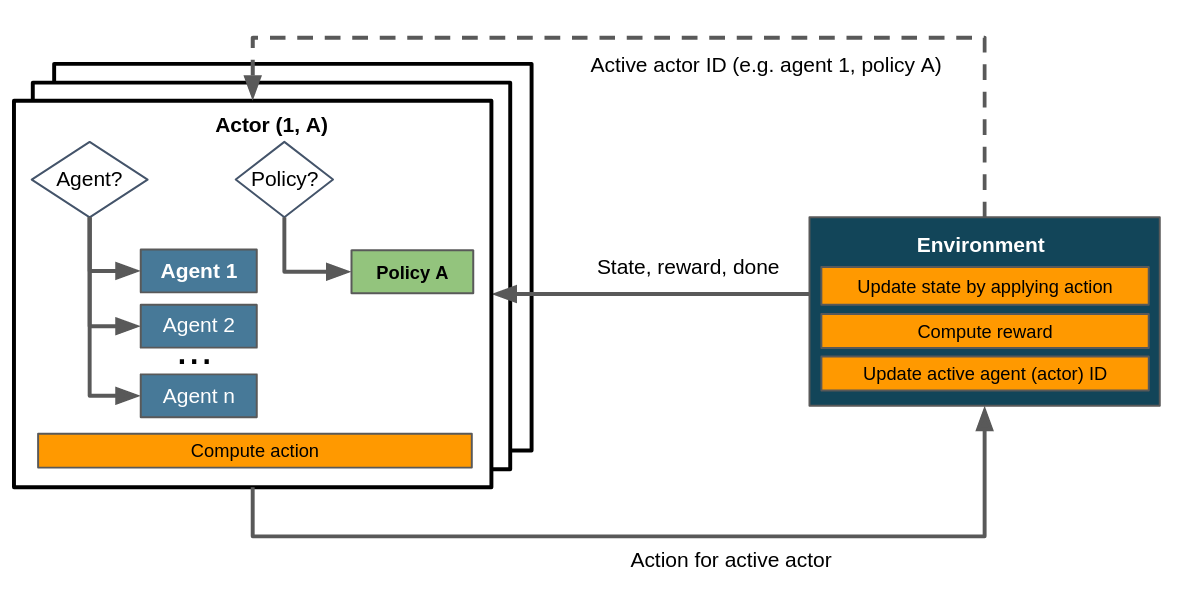
Control flow within a multi-stepping scenario assuming a single agent. The environment keeps track of the active step and adjusts its policy key (via actor_id()) accordingly. Dashed lines denote the exchange of information on demand as opposed to doing so passing it to or returning it from step().¶
When comparing this to the control flow depicted in the article on flat environments you’ll notice that here we consider several policies and therefore several actors - more specifically, in a setup with n sub-steps (or actions per step) we have at least n actors. Consequently the environment has to update its active actor ID, which is not necessary in flat environments.
Relation to Hierarchical RL¶
Hierarchical RL (HRL) describes a hierarchical formulation of reinforcement learning problems: tasks are broken down into (sequences of) subtasks, which are learned in a modular manner. Multi-stepping shares this property with HRL, since it also decomposes a task into a series of subtasks. Furthermorek, the multi-stepping control flow bears strong similarity to the one for hierarchical RL<struct_env_hierarchical> - in fact, multi-stepping could be seen as a special kind of hierarchical RL with a fixed task sequence and a single level of hierarchy.
Relation to Auto-Regressive Action Distributions¶
Multi-stepping is closely related to auto-regressive action distributions (ARAD) as used in in DeepMind’s Grandmaster level in StarCraft II using multi-agent reinforcement learning. Both ARADs and multi-stepping are motivated by a lack of temporal coherency in the sequence of selected actions: if there is some necessary, recurring order of actions, it should be identified it as quickly as possible.
ARADs still execute one action per step, but condition it on the previous state and action instead of the state alone. This allows them to be more sensitive towards such recurring patterns of actions. Multi-stepping allows to incorporate domain knowledge about the correct order of actions or tasks without having to rely on learned autoregressive policies learning, but depends on the environment to incorporate it. ARAD policies do not presuppose (and cannot make use of) any such prior knowledge.
ARADs are not explicitly implemented in Maze, but can be approximated. This can be done by including prior actions in observations supplied to the agent, which should condition the used policy on those actions. If relevant domain knowledge is available, we recommend to implement the multi-stepping though.