Flat Environments¶
Note
- Recommended reads prior to this article:
All instantiable environments in Maze are subclasses of StructuredEnv. Structured environments are discussed in Control Flows with Structured Environments, which we recommend to read prior to this article. Flat environments in our terminology are those utilizing a single actor and a single policy, i. e. a single actor, and conducting one action per step. Within Maze, flat environments are a special case of structured environments.
An exemplary implementation of a flat environment for the stock cutting problem can be found here.
Control Flow¶
Let’s revisit a classic depiction of a RL control flow first:
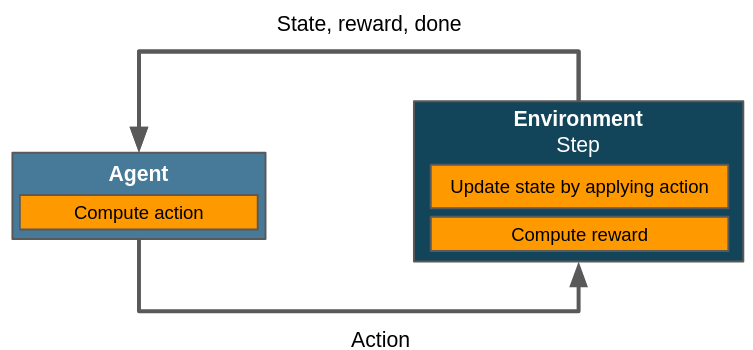
Simplified control flow within a flat scenario. The agent selects an action, the environment updates its state and computes the reward. There is no need to distinguish between different policies or agents since we only have one of each. actor_id() should always return the same value.¶
A more general framework however needs to be able to integrate multiple agents and policies into its control flow. Maze does this by implementing actors, which are abstractions introduced in the RL literature to represent one policy applied on or used by one agent. The figure above collapses the concepts of policy, agent and actor into a single entity for the sake of simplicity. The actual control flow for a flat environment in Maze is closer to this:
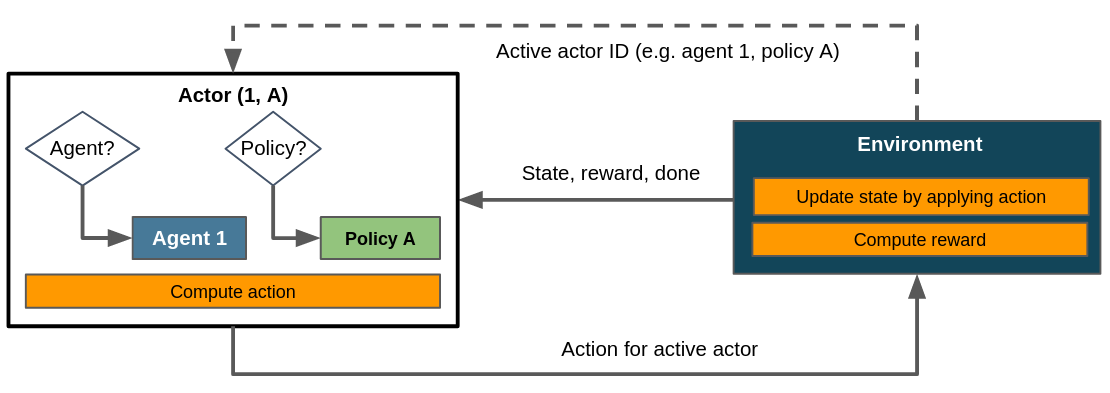
More accurate control flow for a flat environment in Maze, showing how the actor mechanism integrates agent and policy. Dashed lines denote the exchange of information on demand as opposed to doing so passing it to or returning it from step().¶
A flat environment hence always utilizes the same actor, i.e. the same policy for the same agent. Due to the lack of other actors there is no need for the environment to ever update its active actor ID. The concept of actors is crucial to the flexibility of Maze, since it allows to scale up the number of agents, policies or both. This enables the application of RL to a wider range of use cases and exploit properties of the respective domains more efficiently.