Policies, Critics and Agents¶
Depending on the domain and task we are working on we rely on different trainers (algorithm classes) to appropriately address the problem at hand. This in turn implies different requirements for the respective models and contained policy and value estimators.
The figure below provides a conceptual overview of the model classes contained in Maze and relates them to compatible algorithm classes and trainers.
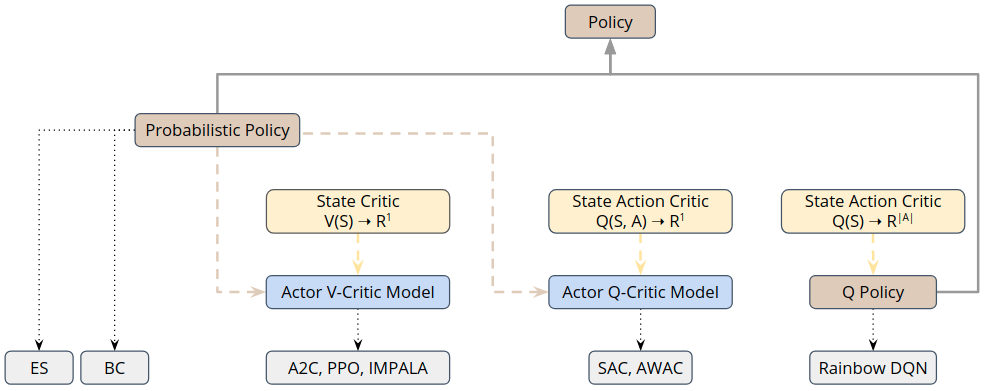
Note that all policy and critics are compatible with Structured Environments.
Policies (Actors)¶
An agent holds one or more policies and acts (selects actions) according to these policies. Each policy consists of one ore more policy networks. This might be for example required in (1) multi-agent RL settings where each agents acts according to its distinct policy network or (2) when working with auto-regressive action spaces or multi-step environments.
In case of Policy Gradient Methods, such as the actor-critic learners A2C or PPO, we rely on a probabilistic policy defining a conditional action selection probability distribution \(\pi(a|s)\) given the current State \(s\).
In case of value-based methods, such as DQN, the Q-policy is defined via the state-action value function \(Q(s, a)\) (e.g, by selecting the action with highest Q value: \(\mathrm{argmax}_a Q(s, a)\)).
Value Functions (Critics)¶
Maze so far supports two different kinds of critics. A standard state critic represented via a scalar value function \(V(S)\) and a state-action critic represented either via a scalar state-action value function \(Q(S, A)\) or its vectorized equivalent \(Q(S)\) predicting the state-action values for all actions at once.
Analogously to policies each critic holds one or more value networks depending on the current usage scenario we are in (auto-regressive, multi-step, multi-agent, …). The table below provides an overview of the different critics styles.
State Critic \(V(S)\) |
|
Each sub-step or actor gets its individual state critic. |
|
One state critic is shared across all sub-steps or actors. |
|
State-Action Critic \(Q(S, A)\) |
|
Each sub-step or actor gets its individual state-action critic. |
|
One state-action critic is shared across all sub-steps or actors. |
Actor-Critics¶
To conveniently work with algorithms such as A2C, PPO, IMPALA or SAC we provide a
TorchActorCritic model
to unifying the different policy and critic types into one model.
Where to Go Next¶
For further details please see the reference documentation.
To see how to actually implement policy and critic networks see the Perception Module.
You can see the list of available probability distributions for probabilistic policies.
You can also follow up on the available Maze trainers.